 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDORB: Dynamically Optimizing Multiple Rewards with Bandits
Paper and Code
Nov 15, 2020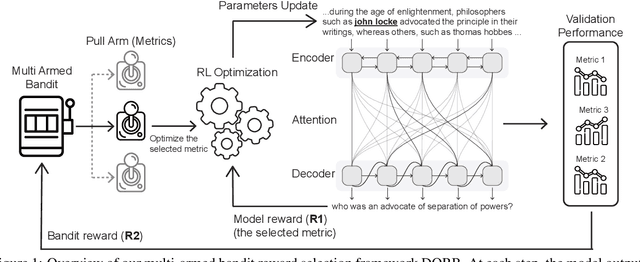
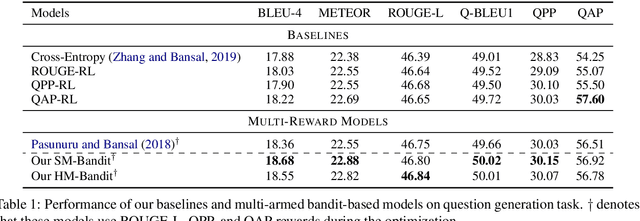
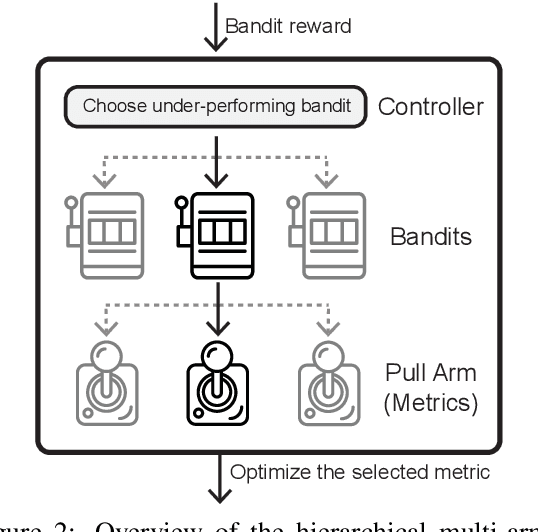
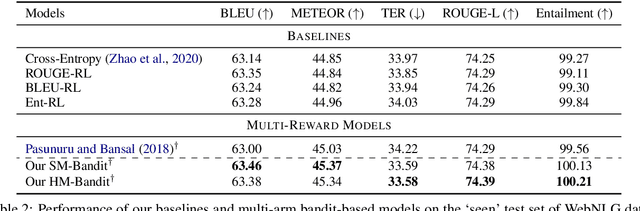
Policy gradients-based reinforcement learning has proven to be a promising approach for directly optimizing non-differentiable evaluation metrics for language generation tasks. However, optimizing for a specific metric reward leads to improvements in mostly that metric only, suggesting that the model is gaming the formulation of that metric in a particular way without often achieving real qualitative improvements. Hence, it is more beneficial to make the model optimize multiple diverse metric rewards jointly. While appealing, this is challenging because one needs to manually decide the importance and scaling weights of these metric rewards. Further, it is important to consider using a dynamic combination and curriculum of metric rewards that flexibly changes over time. Considering the above aspects, in our work, we automate the optimization of multiple metric rewards simultaneously via a multi-armed bandit approach (DORB), where at each round, the bandit chooses which metric reward to optimize next, based on expected arm gains. We use the Exp3 algorithm for bandits and formulate two approaches for bandit rewards: (1) Single Multi-reward Bandit (SM-Bandit); (2) Hierarchical Multi-reward Bandit (HM-Bandit). We empirically show the effectiveness of our approaches via various automatic metrics and human evaluation on two important NLG tasks: question generation and data-to-text generation, including on an unseen-test transfer setup. Finally, we present interpretable analyses of the learned bandit curriculum over the optimized rewards.