 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding Training Efficiency of Deep Learning Recommendation Models at Scale
Paper and Code
Nov 11, 2020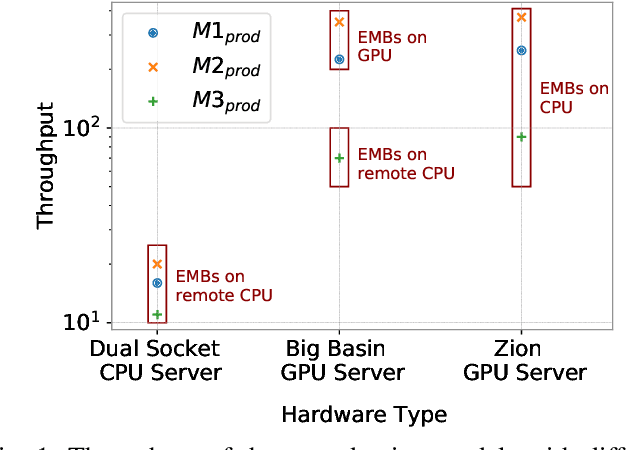
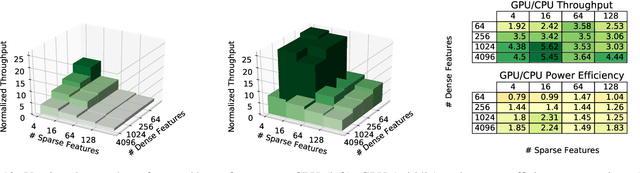
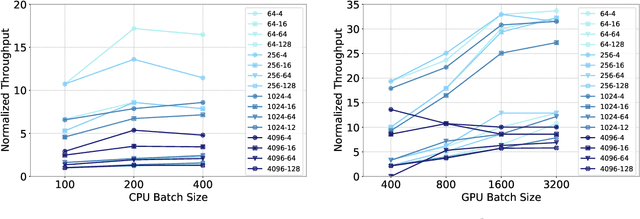
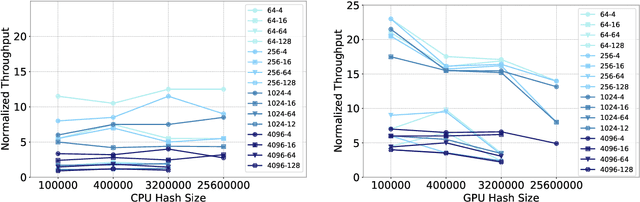
The use of GPUs has proliferated for machine learning workflows and is now considered mainstream for many deep learning models. Meanwhile, when training state-of-the-art personal recommendation models, which consume the highest number of compute cycles at our large-scale datacenters, the use of GPUs came with various challenges due to having both compute-intensive and memory-intensive components. GPU performance and efficiency of these recommendation models are largely affected by model architecture configurations such as dense and sparse features, MLP dimensions. Furthermore, these models often contain large embedding tables that do not fit into limited GPU memory. The goal of this paper is to explain the intricacies of using GPUs for training recommendation models, factors affecting hardware efficiency at scale, and learnings from a new scale-up GPU server design, Zion.