 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDimension-agnostic inference
Paper and Code
Nov 10, 2020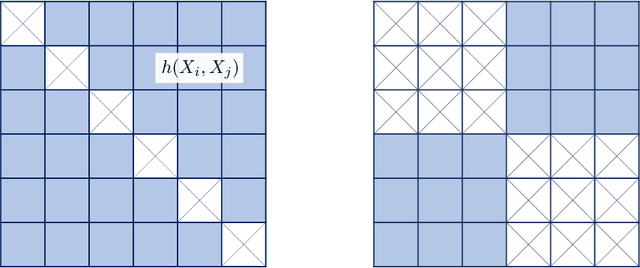
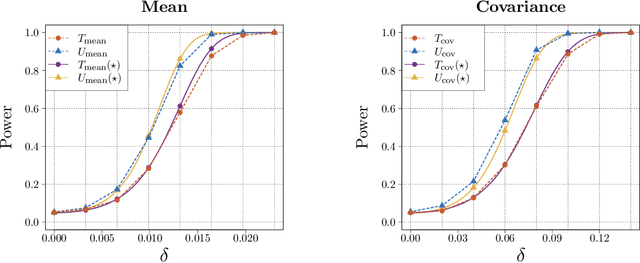
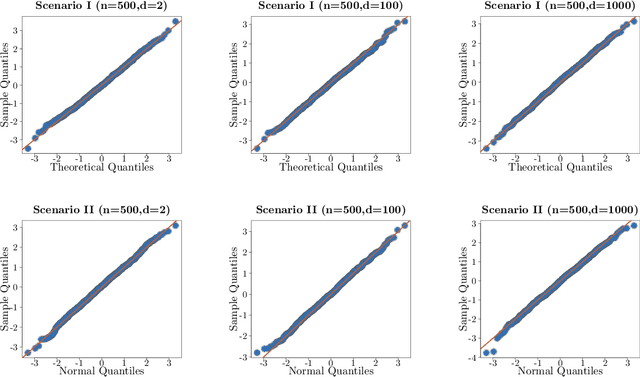
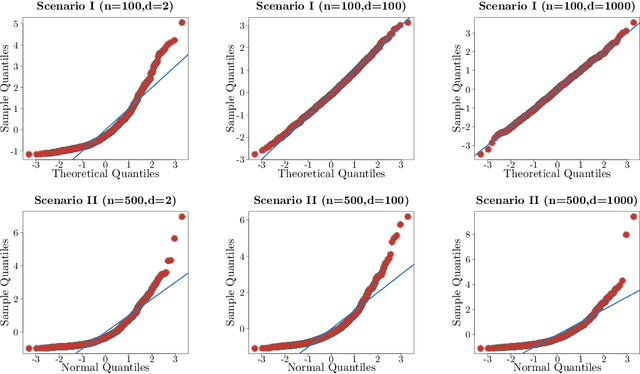
Classical asymptotic theory for statistical hypothesis testing, for example Wilks' theorem for likelihood ratios, usually involves calibrating the test statistic by fixing the dimension $d$ while letting the sample size $n$ increase to infinity. In the last few decades, a great deal of effort has been dedicated towards understanding how these methods behave in high-dimensional settings, where $d_n$ and $n$ both increase to infinity together at some prescribed relative rate. This often leads to different tests in the two settings, depending on the assumptions about the dimensionality. This leaves the practitioner in a bind: given a dataset with 100 samples in 20 dimensions, should they calibrate by assuming $n \gg d$, or $d_n/n \approx 0.2$? This paper considers the goal of dimension-agnostic inference---developing methods whose validity does not depend on any assumption on $d_n$. We describe one generic approach that uses variational representations of existing test statistics along with sample-splitting and self-normalization (studentization) to produce a Gaussian limiting null distribution. We exemplify this technique for a handful of classical problems, such as one-sample mean testing, testing if a covariance matrix equals the identity, and kernel methods for testing equality of distributions using degenerate U-statistics like the maximum mean discrepancy. Without explicitly targeting the high-dimensional setting, our tests are shown to be minimax rate-optimal, meaning that the power of our tests cannot be improved further up to a constant factor. A hidden advantage is that our proofs are simple and transparent. We end by describing several fruitful open directions.