 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLAR: A Cross-Lingual Argument Regularizer for Semantic Role Labeling
Paper and Code
Nov 09, 2020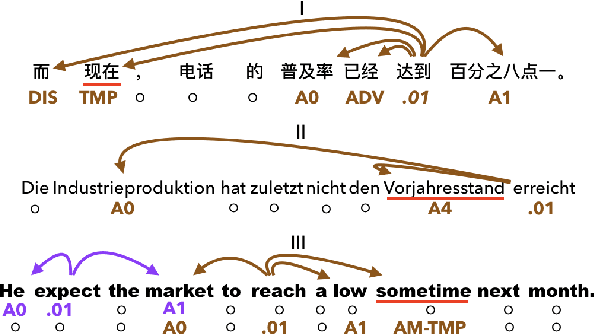
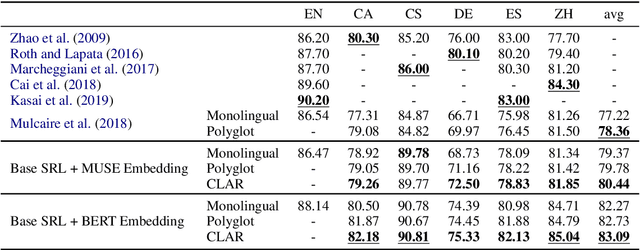
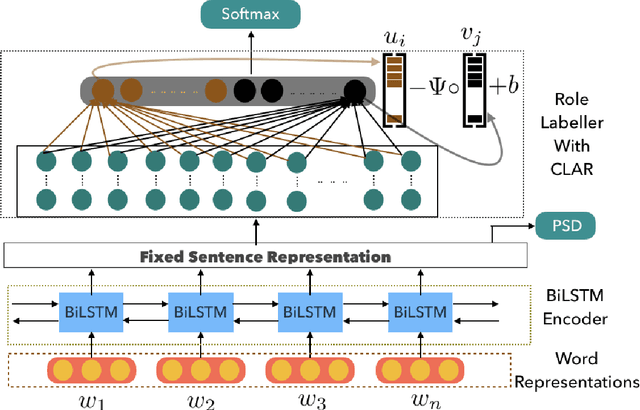

Semantic role labeling (SRL) identifies predicate-argument structure(s) in a given sentence. Although different languages have different argument annotations, polyglot training, the idea of training one model on multiple languages, has previously been shown to outperform monolingual baselines, especially for low resource languages. In fact, even a simple combination of data has been shown to be effective with polyglot training by representing the distant vocabularies in a shared representation space. Meanwhile, despite the dissimilarity in argument annotations between languages, certain argument labels do share common semantic meaning across languages (e.g. adjuncts have more or less similar semantic meaning across languages). To leverage such similarity in annotation space across languages, we propose a method called Cross-Lingual Argument Regularizer (CLAR). CLAR identifies such linguistic annotation similarity across languages and exploits this information to map the target language arguments using a transformation of the space on which source language arguments lie. By doing so, our experimental results show that CLAR consistently improves SRL performance on multiple languages over monolingual and polyglot baselines for low resource languages.