 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimize what matters: Training DNN-HMM Keyword Spotting Model Using End Metric
Paper and Code
Nov 02, 2020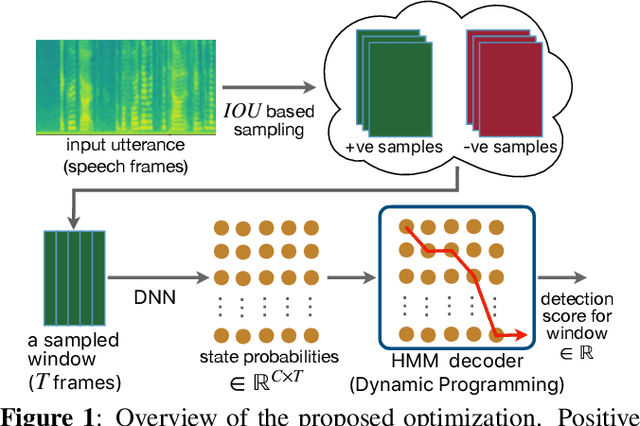
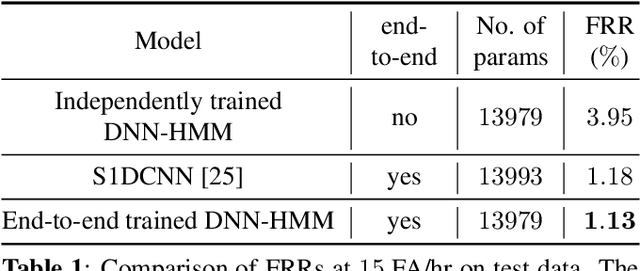
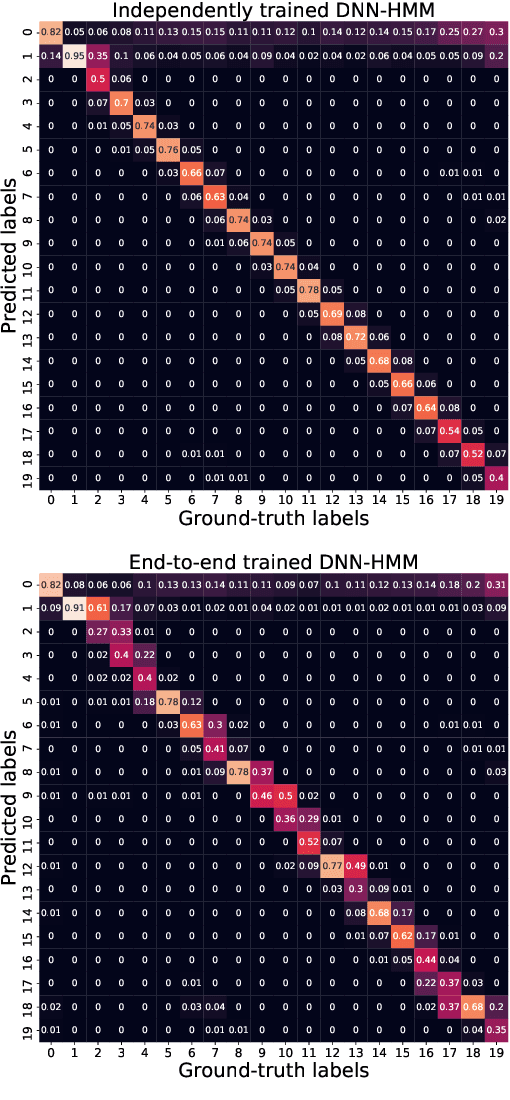
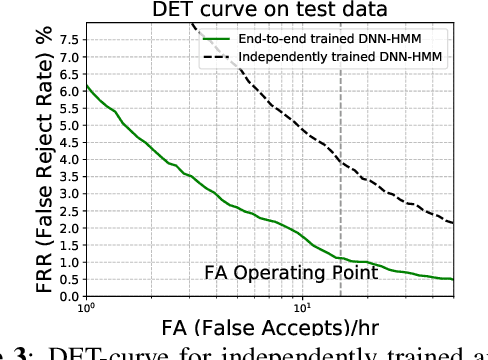
Deep Neural Network--Hidden Markov Model (DNN-HMM) based methods have been successfully used for many always-on keyword spotting algorithms that detect a wake word to trigger a device. The DNN predicts the state probabilities of a given speech frame, while HMM decoder combines the DNN predictions of multiple speech frames to compute the keyword detection score. The DNN, in prior methods, is trained independent of the HMM parameters to minimize the cross-entropy loss between the predicted and the ground-truth state probabilities. The mis-match between the DNN training loss (cross-entropy) and the end metric (detection score) is the main source of sub-optimal performance for the keyword spotting task. We address this loss-metric mismatch with a novel end-to-end training strategy that learns the DNN parameters by optimizing for the detection score. To this end, we make the HMM decoder (dynamic programming) differentiable and back-propagate through it to maximize the score for the keyword and minimize the scores for non-keyword speech segments. Our method does not require any change in the model architecture or the inference framework; therefore, there is no overhead in run-time memory or compute requirements. Moreover, we show significant reduction in false rejection rate (FRR) at the same false trigger experience (> 70% over independent DNN training).