 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph-based Topic Extraction from Vector Embeddings of Text Documents: Application to a Corpus of News Articles
Paper and Code
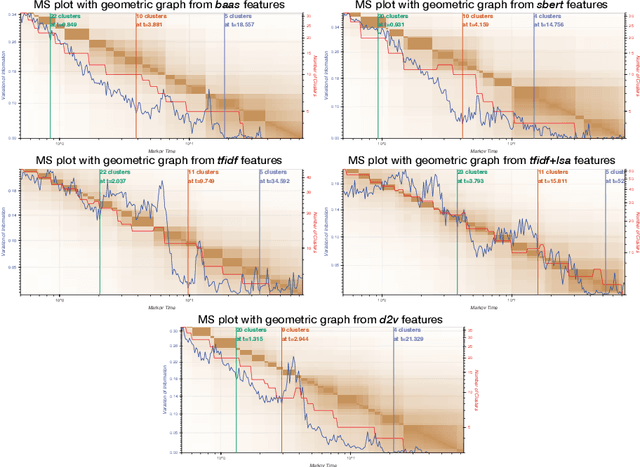
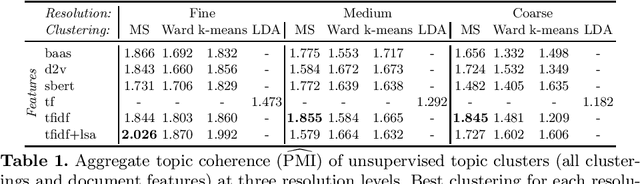
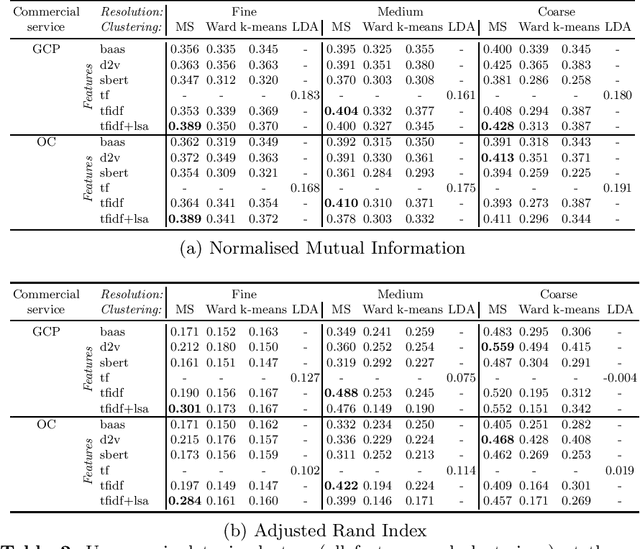
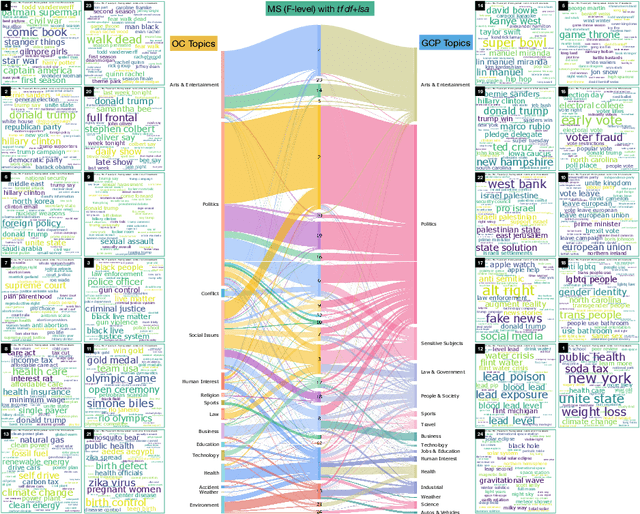
Production of news content is growing at an astonishing rate. To help manage and monitor the sheer amount of text, there is an increasing need to develop efficient methods that can provide insights into emerging content areas, and stratify unstructured corpora of text into `topics' that stem intrinsically from content similarity. Here we present an unsupervised framework that brings together powerful vector embeddings from natural language processing with tools from multiscale graph partitioning that can reveal natural partitions at different resolutions without making a priori assumptions about the number of clusters in the corpus. We show the advantages of graph-based clustering through end-to-end comparisons with other popular clustering and topic modelling methods, and also evaluate different text vector embeddings, from classic Bag-of-Words to Doc2Vec to the recent transformers based model Bert. This comparative work is showcased through an analysis of a corpus of US news coverage during the presidential election year of 2016.