 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecoupling Pronunciation and Language for End-to-end Code-switching Automatic Speech Recognition
Paper and Code
Oct 28, 2020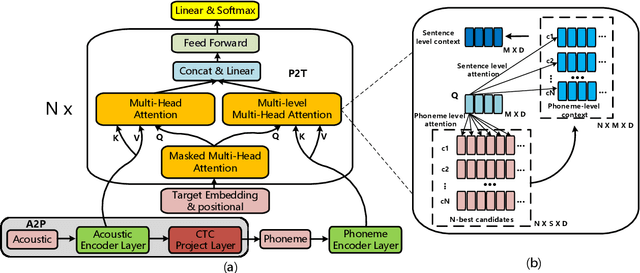
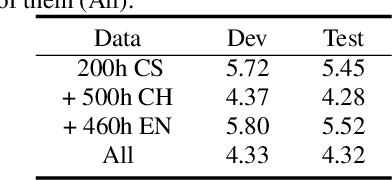
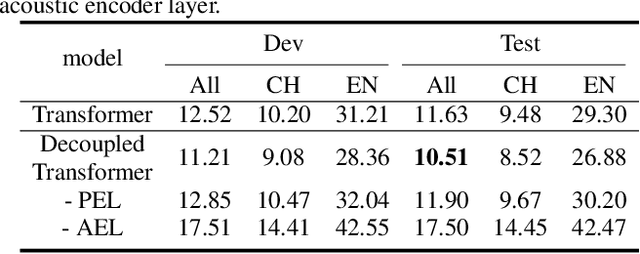
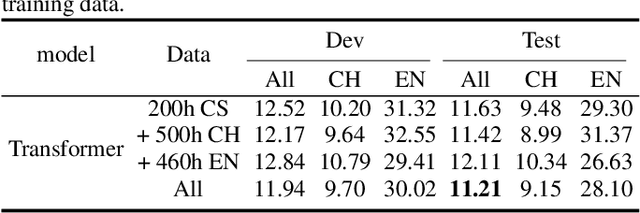
Despite the recent significant advances witnessed in end-to-end (E2E) ASR system for code-switching, hunger for audio-text paired data limits the further improvement of the models' performance. In this paper, we propose a decoupled transformer model to use monolingual paired data and unpaired text data to alleviate the problem of code-switching data shortage. The model is decoupled into two parts: audio-to-phoneme (A2P) network and phoneme-to-text (P2T) network. The A2P network can learn acoustic pattern scenarios using large-scale monolingual paired data. Meanwhile, it generates multiple phoneme sequence candidates for single audio data in real-time during the training process. Then the generated phoneme-text paired data is used to train the P2T network. This network can be pre-trained with large amounts of external unpaired text data. By using monolingual data and unpaired text data, the decoupled transformer model reduces the high dependency on code-switching paired training data of E2E model to a certain extent. Finally, the two networks are optimized jointly through attention fusion. We evaluate the proposed method on the public Mandarin-English code-switching dataset. Compared with our transformer baseline, the proposed method achieves 18.14% relative mix error rate reduction.