 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImpossibility Results for Grammar-Compressed Linear Algebra
Paper and Code
Oct 27, 2020
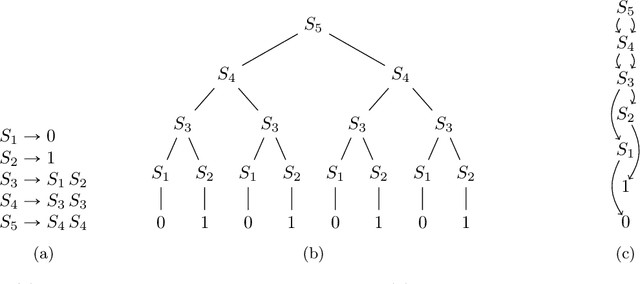
To handle vast amounts of data, it is natural and popular to compress vectors and matrices. When we compress a vector from size $N$ down to size $n \ll N$, it certainly makes it easier to store and transmit efficiently, but does it also make it easier to process? In this paper we consider lossless compression schemes, and ask if we can run our computations on the compressed data as efficiently as if the original data was that small. That is, if an operation has time complexity $T(\rm{inputsize})$, can we perform it on the compressed representation in time $T(n)$ rather than $T(N)$? We consider the most basic linear algebra operations: inner product, matrix-vector multiplication, and matrix multiplication. In particular, given two compressed vectors, can we compute their inner product in time $O(n)$? Or perhaps we must decompress first and then multiply, spending $\Omega(N)$ time? The answer depends on the compression scheme. While for simple ones such as Run-Length-Encoding (RLE) the inner product can be done in $O(n)$ time, we prove that this is impossible for compressions from a richer class: essentially $n^2$ or even larger runtimes are needed in the worst case (under complexity assumptions). This is the class of grammar-compressions containing most popular methods such as the Lempel-Ziv family. These schemes are more compressing than the simple RLE, but alas, we prove that performing computations on them is much harder.