 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralized Iris Presentation Attack Detection Algorithm under Cross-Database Settings
Paper and Code
Oct 25, 2020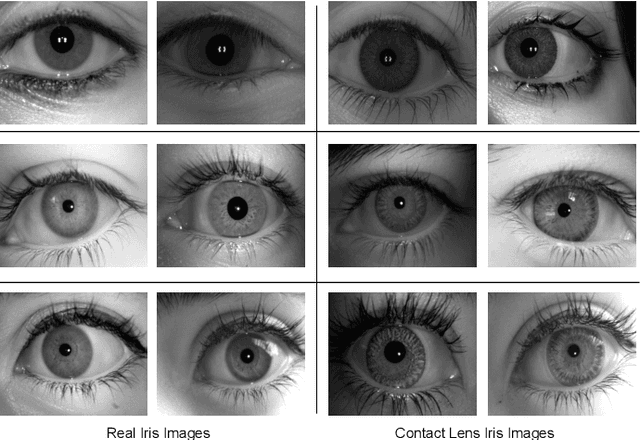

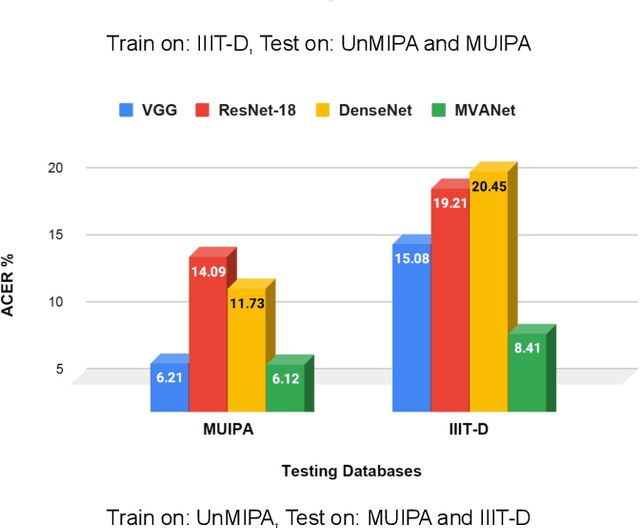

Presentation attacks are posing major challenges to most of the biometric modalities. Iris recognition, which is considered as one of the most accurate biometric modality for person identification, has also been shown to be vulnerable to advanced presentation attacks such as 3D contact lenses and textured lens. While in the literature, several presentation attack detection (PAD) algorithms are presented; a significant limitation is the generalizability against an unseen database, unseen sensor, and different imaging environment. To address this challenge, we propose a generalized deep learning-based PAD network, MVANet, which utilizes multiple representation layers. It is inspired by the simplicity and success of hybrid algorithm or fusion of multiple detection networks. The computational complexity is an essential factor in training deep neural networks; therefore, to reduce the computational complexity while learning multiple feature representation layers, a fixed base model has been used. The performance of the proposed network is demonstrated on multiple databases such as IIITD-WVU MUIPA and IIITD-CLI databases under cross-database training-testing settings, to assess the generalizability of the proposed algorithm.