 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTensor Casting: Co-Designing Algorithm-Architecture for Personalized Recommendation Training
Paper and Code
Oct 25, 2020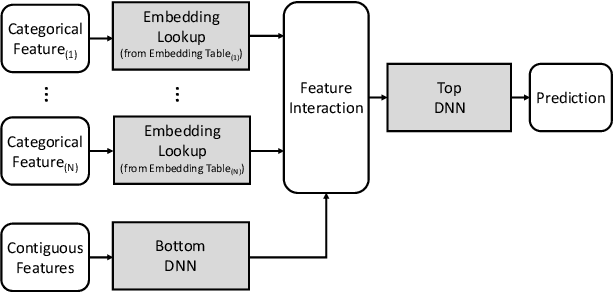
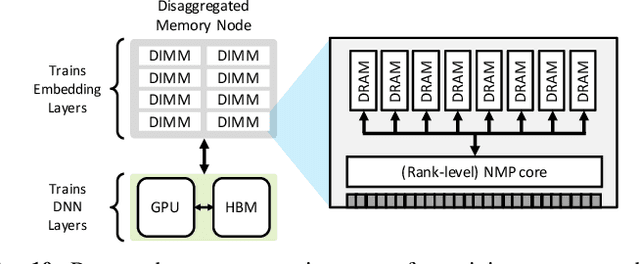
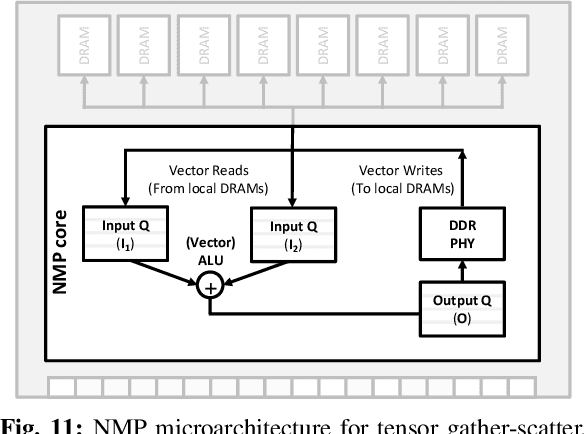
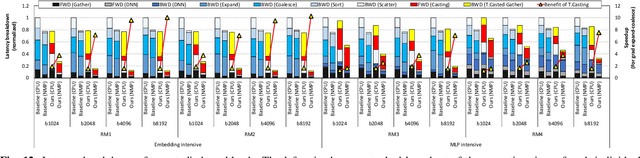
Personalized recommendations are one of the most widely deployed machine learning (ML) workload serviced from cloud datacenters. As such, architectural solutions for high-performance recommendation inference have recently been the target of several prior literatures. Unfortunately, little have been explored and understood regarding the training side of this emerging ML workload. In this paper, we first perform a detailed workload characterization study on training recommendations, root-causing sparse embedding layer training as one of the most significant performance bottlenecks. We then propose our algorithm-architecture co-design called Tensor Casting, which enables the development of a generic accelerator architecture for tensor gather-scatter that encompasses all the key primitives of training embedding layers. When prototyped on a real CPU-GPU system, Tensor Casting provides 1.9-21x improvements in training throughput compared to state-of-the-art approaches.