 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClustering Contextualized Representations of Text for Unsupervised Syntax Induction
Paper and Code
Oct 24, 2020
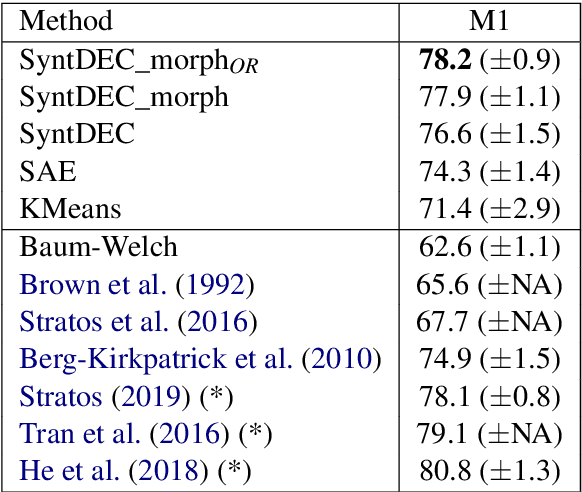
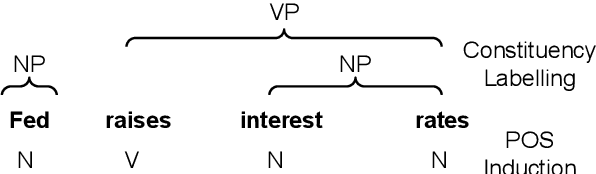
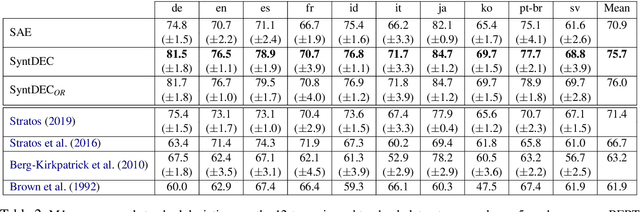
We explore clustering of contextualized text representations for two unsupervised syntax induction tasks: part of speech induction (POSI) and constituency labelling (CoLab). We propose a deep embedded clustering approach which jointly transforms these representations into a lower dimension cluster friendly space and clusters them. We further enhance these representations by augmenting them with task-specific representations. We also explore the effectiveness of multilingual representations for different tasks and languages. With this work, we establish the first strong baselines for unsupervised syntax induction using contextualized text representations. We report competitive performance on 45-tag POSI, state-of-the-art performance on 12-tag POSI across 10 languages, and competitive results on CoLab.