 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Passage Retrieval with Improved Negative Contrast
Paper and Code
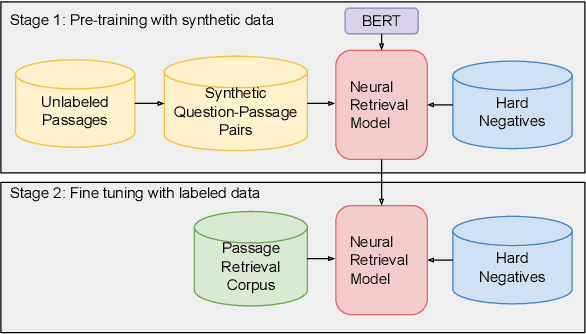
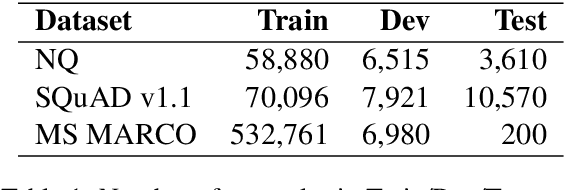
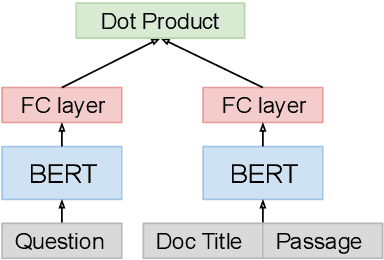
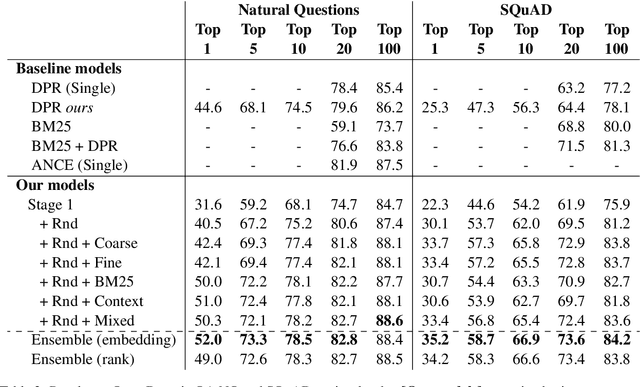
In this paper we explore the effects of negative sampling in dual encoder models used to retrieve passages for automatic question answering. We explore four negative sampling strategies that complement the straightforward random sampling of negatives, typically used to train dual encoder models. Out of the four strategies, three are based on retrieval and one on heuristics. Our retrieval-based strategies are based on the semantic similarity and the lexical overlap between questions and passages. We train the dual encoder models in two stages: pre-training with synthetic data and fine tuning with domain-specific data. We apply negative sampling to both stages. The approach is evaluated in two passage retrieval tasks. Even though it is not evident that there is one single sampling strategy that works best in all the tasks, it is clear that our strategies contribute to improving the contrast between the response and all the other passages. Furthermore, mixing the negatives from different strategies achieve performance on par with the best performing strategy in all tasks. Our results establish a new state-of-the-art level of performance on two of the open-domain question answering datasets that we evaluated.