Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShow and Speak: Directly Synthesize Spoken Description of Images
Paper and Code
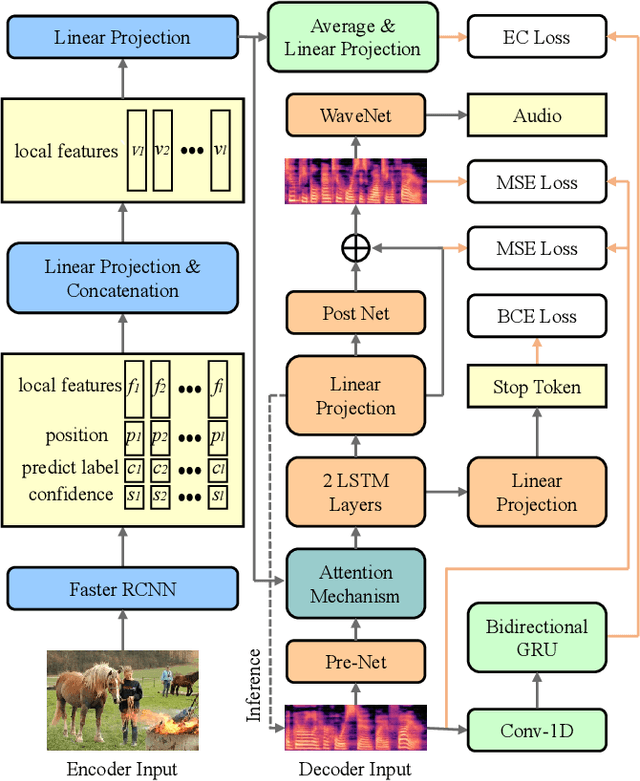

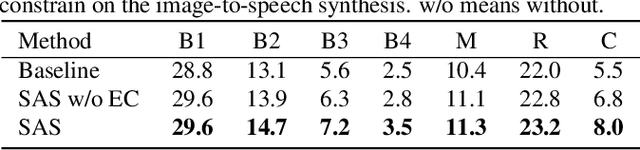

This paper proposes a new model, referred to as the show and speak (SAS) model that, for the first time, is able to directly synthesize spoken descriptions of images, bypassing the need for any text or phonemes. The basic structure of SAS is an encoder-decoder architecture that takes an image as input and predicts the spectrogram of speech that describes this image. The final speech audio is obtained from the predicted spectrogram via WaveNet. Extensive experiments on the public benchmark database Flickr8k demonstrate that the proposed SAS is able to synthesize natural spoken descriptions for images, indicating that synthesizing spoken descriptions for images while bypassing text and phonemes is feasible.
View paper on