 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimple Neighborhood Representative Pre-processing Boosts Outlier Detectors
Paper and Code
Oct 11, 2020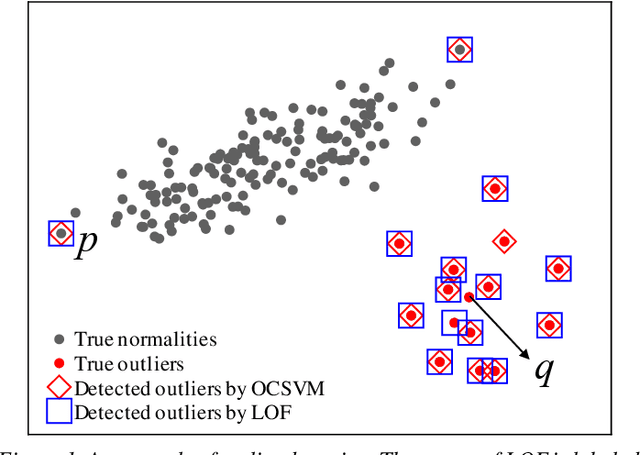

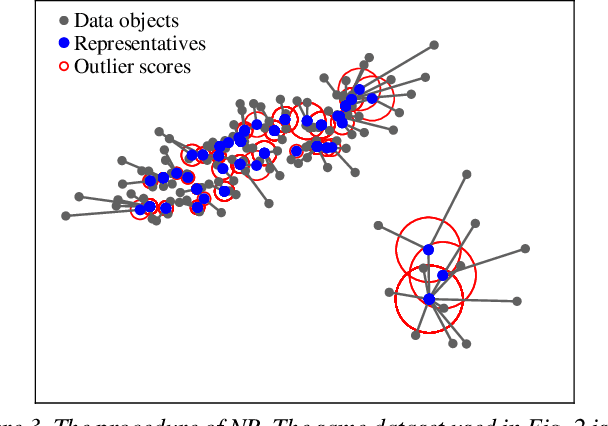
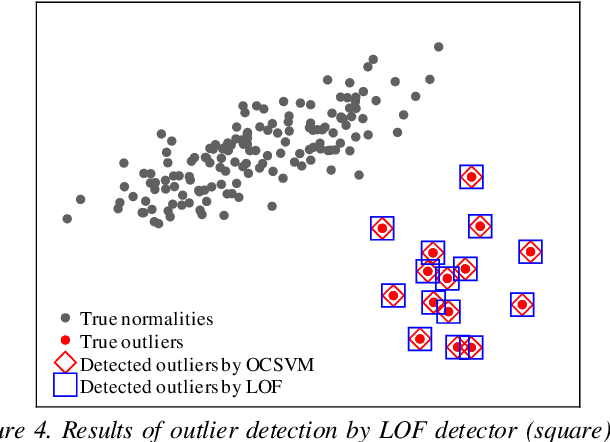
Outlier detectors heavily rely on data distribution. All outlier detectors will become ineffective, for example, when data has collective outliers or a large portion of outliers. To better handle this issue, we propose a pre-processing technique called neighborhood representative. The neighborhood representative first selects a subset of representative objects from data, then employs outlier detectors to score the representatives. The non-representative data objects share the same score with the representative object nearby. The proposed technique is essentially an add-on to most existing outlier detector as it can improve 16% accuracy (from 0.64 AUC to 0.74 AUC) on average evaluated on six datasets with nine state-of-the-art outlier detectors. In datasets with fewer outliers, the proposed technique can still improve most of the tested outlier detectors.