 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComputationally and Statistically Efficient Truncated Regression
Paper and Code
Oct 22, 2020
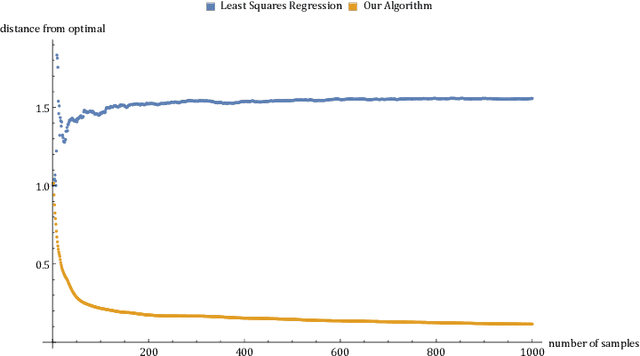
We provide a computationally and statistically efficient estimator for the classical problem of truncated linear regression, where the dependent variable $y = w^T x + \epsilon$ and its corresponding vector of covariates $x \in R^k$ are only revealed if the dependent variable falls in some subset $S \subseteq R$; otherwise the existence of the pair $(x, y)$ is hidden. This problem has remained a challenge since the early works of [Tobin 1958, Amemiya 1973, Hausman and Wise 1977], its applications are abundant, and its history dates back even further to the work of Galton, Pearson, Lee, and Fisher. While consistent estimators of the regression coefficients have been identified, the error rates are not well-understood, especially in high dimensions. Under a thickness assumption about the covariance matrix of the covariates in the revealed sample, we provide a computationally efficient estimator for the coefficient vector $w$ from $n$ revealed samples that attains $l_2$ error $\tilde{O}(\sqrt{k/n})$. Our estimator uses Projected Stochastic Gradient Descent (PSGD) without replacement on the negative log-likelihood of the truncated sample. For the statistically efficient estimation we only need oracle access to the set $S$.In order to achieve computational efficiency we need to assume that $S$ is a union of a finite number of intervals but still can be complicated. PSGD without replacement must be restricted to an appropriately defined convex cone to guarantee that the negative log-likelihood is strongly convex, which in turn is established using concentration of matrices on variables with sub-exponential tails. We perform experiments on simulated data to illustrate the accuracy of our estimator. As a corollary, we show that SGD learns the parameters of single-layer neural networks with noisy activation functions.