Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNADI 2020: The First Nuanced Arabic Dialect Identification Shared Task
Paper and Code
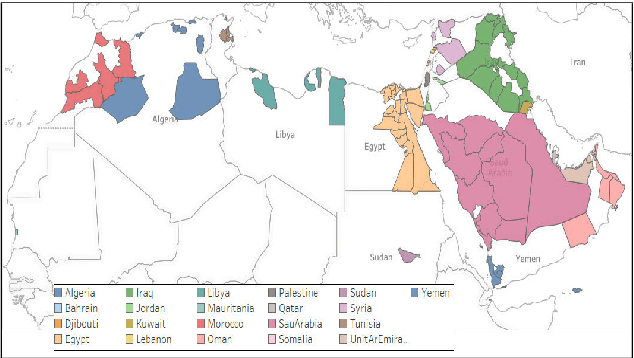
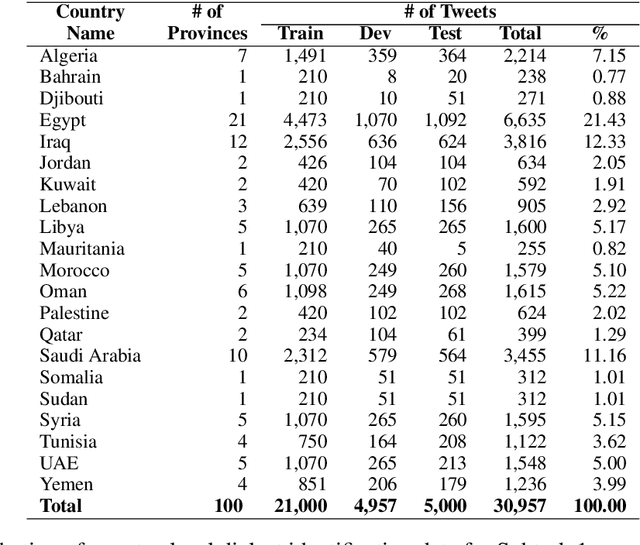
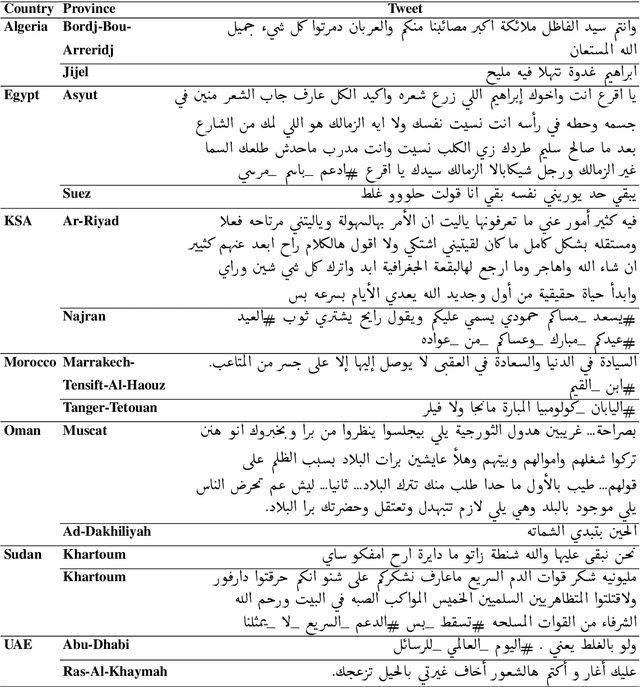
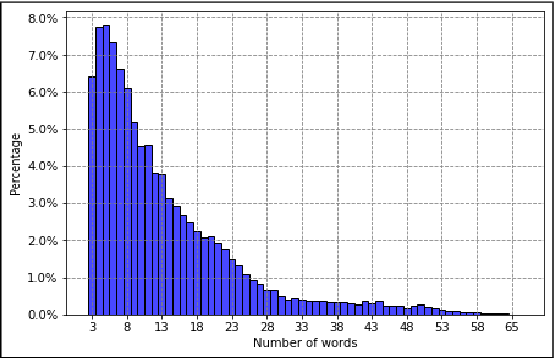
We present the results and findings of the First Nuanced Arabic Dialect Identification Shared Task (NADI). This Shared Task includes two subtasks: country-level dialect identification (Subtask 1) and province-level sub-dialect identification (Subtask 2). The data for the shared task covers a total of 100 provinces from 21 Arab countries and are collected from the Twitter domain. As such, NADI is the first shared task to target naturally-occurring fine-grained dialectal text at the sub-country level. A total of 61 teams from 25 countries registered to participate in the tasks, thus reflecting the interest of the community in this area. We received 47 submissions for Subtask 1 from 18 teams and 9 submissions for Subtask 2 from 9 teams.
* Accepted in The Fifth Arabic Natural Language Processing Workshop
(WANLP 2020)
View paper on