 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWaveTransformer: A Novel Architecture for Audio Captioning Based on Learning Temporal and Time-Frequency Information
Paper and Code
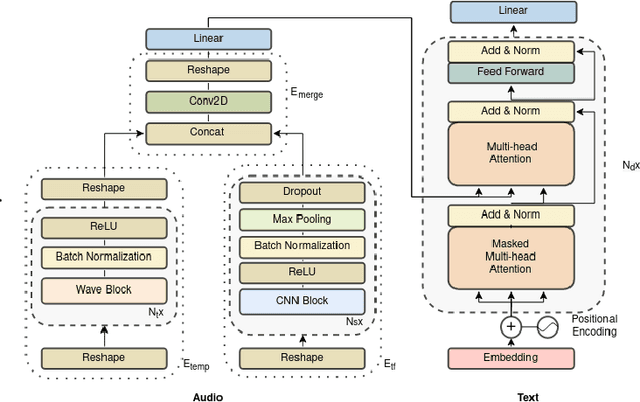

Automated audio captioning (AAC) is a novel task, where a method takes as an input an audio sample and outputs a textual description (i.e. a caption) of its contents. Most AAC methods are adapted from from image captioning of machine translation fields. In this work we present a novel AAC novel method, explicitly focused on the exploitation of the temporal and time-frequency patterns in audio. We employ three learnable processes for audio encoding, two for extracting the local and temporal information, and one to merge the output of the previous two processes. To generate the caption, we employ the widely used Transformer decoder. We assess our method utilizing the freely available splits of Clotho dataset. Our results increase previously reported highest SPIDEr to 17.3, from 16.2.