 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat is More Likely to Happen Next? Video-and-Language Future Event Prediction
Paper and Code


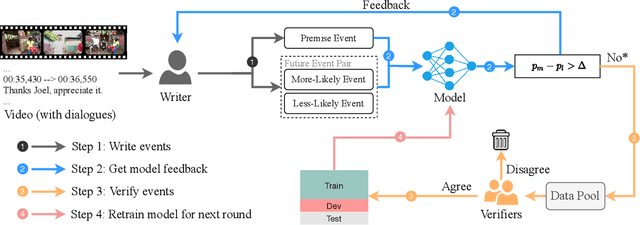
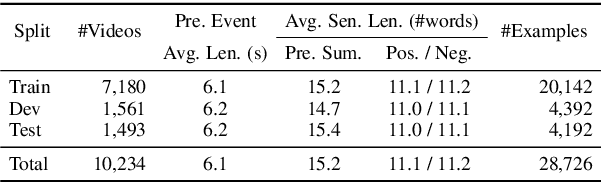
Given a video with aligned dialogue, people can often infer what is more likely to happen next. Making such predictions requires not only a deep understanding of the rich dynamics underlying the video and dialogue, but also a significant amount of commonsense knowledge. In this work, we explore whether AI models are able to learn to make such multimodal commonsense next-event predictions. To support research in this direction, we collect a new dataset, named Video-and-Language Event Prediction (VLEP), with 28,726 future event prediction examples (along with their rationales) from 10,234 diverse TV Show and YouTube Lifestyle Vlog video clips. In order to promote the collection of non-trivial challenging examples, we employ an adversarial human-and-model-in-the-loop data collection procedure. We also present a strong baseline incorporating information from video, dialogue, and commonsense knowledge. Experiments show that each type of information is useful for this challenging task, and that compared to the high human performance on VLEP, our model provides a good starting point but leaves large room for future work. Our dataset and code are available at: https://github.com/jayleicn/VideoLanguageFuturePred