 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-label Few/Zero-shot Learning with Knowledge Aggregated from Multiple Label Graphs
Paper and Code
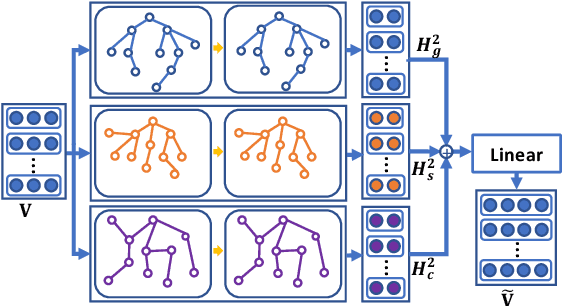
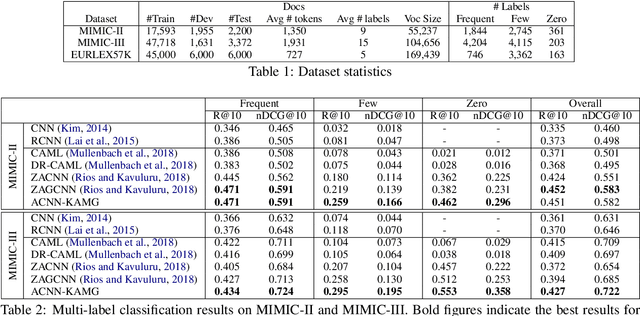

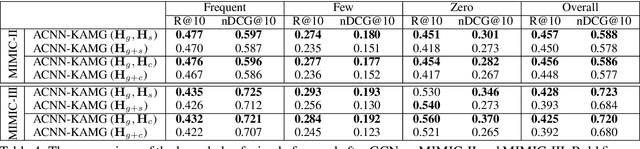
Few/Zero-shot learning is a big challenge of many classifications tasks, where a classifier is required to recognise instances of classes that have very few or even no training samples. It becomes more difficult in multi-label classification, where each instance is labelled with more than one class. In this paper, we present a simple multi-graph aggregation model that fuses knowledge from multiple label graphs encoding different semantic label relationships in order to study how the aggregated knowledge can benefit multi-label zero/few-shot document classification. The model utilises three kinds of semantic information, i.e., the pre-trained word embeddings, label description, and pre-defined label relations. Experimental results derived on two large clinical datasets (i.e., MIMIC-II and MIMIC-III) and the EU legislation dataset show that methods equipped with the multi-graph knowledge aggregation achieve significant performance improvement across almost all the measures on few/zero-shot labels.