 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultilingual Argument Mining: Datasets and Analysis
Paper and Code
Oct 13, 2020
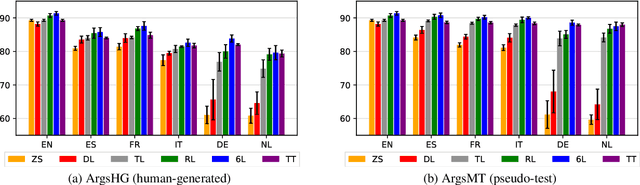
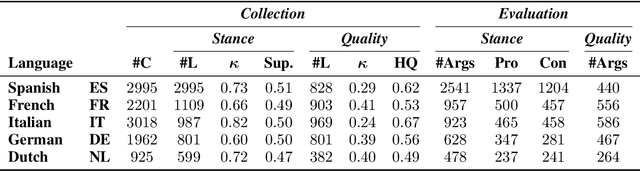
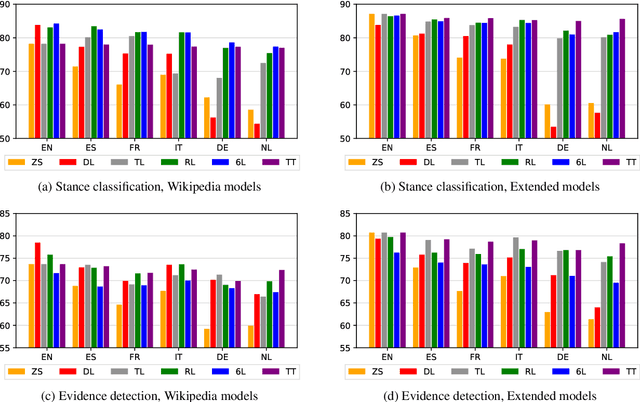
The growing interest in argument mining and computational argumentation brings with it a plethora of Natural Language Understanding (NLU) tasks and corresponding datasets. However, as with many other NLU tasks, the dominant language is English, with resources in other languages being few and far between. In this work, we explore the potential of transfer learning using the multilingual BERT model to address argument mining tasks in non-English languages, based on English datasets and the use of machine translation. We show that such methods are well suited for classifying the stance of arguments and detecting evidence, but less so for assessing the quality of arguments, presumably because quality is harder to preserve under translation. In addition, focusing on the translate-train approach, we show how the choice of languages for translation, and the relations among them, affect the accuracy of the resultant model. Finally, to facilitate evaluation of transfer learning on argument mining tasks, we provide a human-generated dataset with more than 10k arguments in multiple languages, as well as machine translation of the English datasets.