 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBERT-EMD: Many-to-Many Layer Mapping for BERT Compression with Earth Mover's Distance
Paper and Code
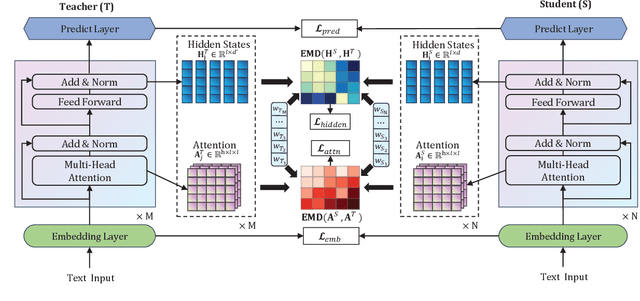
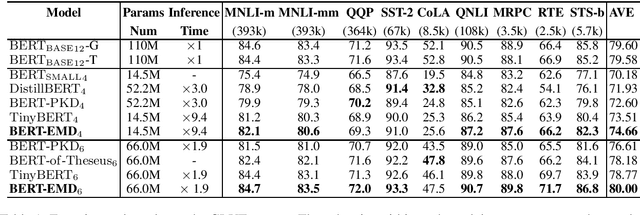
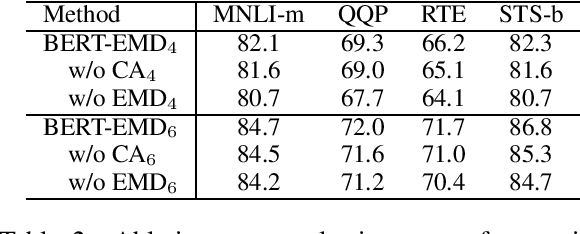
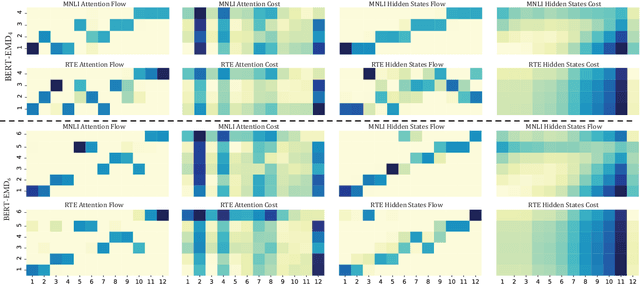
Pre-trained language models (e.g., BERT) have achieved significant success in various natural language processing (NLP) tasks. However, high storage and computational costs obstruct pre-trained language models to be effectively deployed on resource-constrained devices. In this paper, we propose a novel BERT distillation method based on many-to-many layer mapping, which allows each intermediate student layer to learn from any intermediate teacher layers. In this way, our model can learn from different teacher layers adaptively for various NLP tasks. %motivated by the intuition that different NLP tasks require different levels of linguistic knowledge contained in the intermediate layers of BERT. In addition, we leverage Earth Mover's Distance (EMD) to compute the minimum cumulative cost that must be paid to transform knowledge from teacher network to student network. EMD enables the effective matching for many-to-many layer mapping. %EMD can be applied to network layers with different sizes and effectively measures semantic distance between the teacher network and student network. Furthermore, we propose a cost attention mechanism to learn the layer weights used in EMD automatically, which is supposed to further improve the model's performance and accelerate convergence time. Extensive experiments on GLUE benchmark demonstrate that our model achieves competitive performance compared to strong competitors in terms of both accuracy and model compression.