 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClass-Weighted Evaluation Metrics for Imbalanced Data Classification
Paper and Code
Oct 12, 2020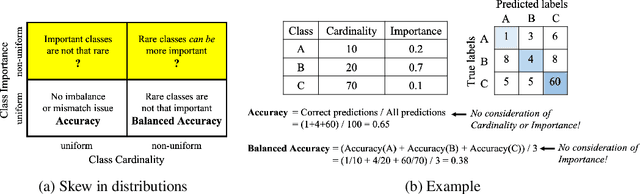
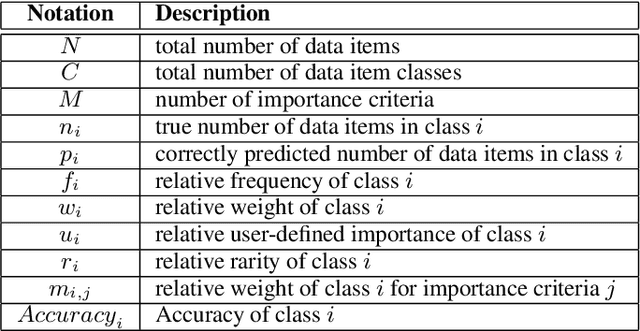
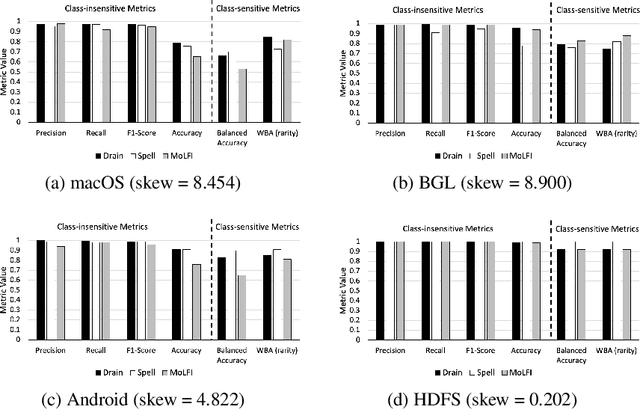
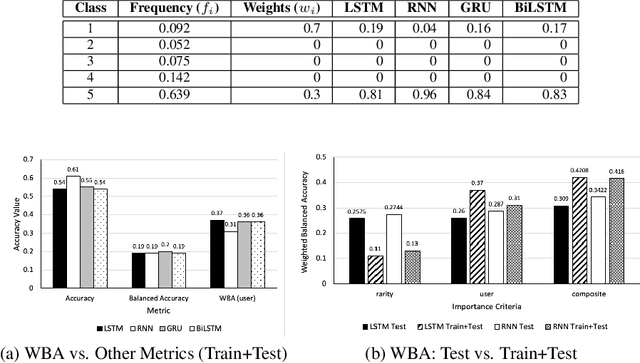
Class distribution skews in imbalanced datasets may lead to models with prediction bias towards majority classes, making fair assessment of classifiers a challenging task. Balanced Accuracy is a popular metric used to evaluate a classifier's prediction performance under such scenarios. However, this metric falls short when classes vary in importance, especially when class importance is skewed differently from class cardinality distributions. In this paper, we propose a simple and general-purpose evaluation framework for imbalanced data classification that is sensitive to arbitrary skews in class cardinalities and importances. Experiments with several state-of-the-art classifiers tested on real-world datasets and benchmarks from two different domains show that our new framework is more effective than Balanced Accuracy -- not only in evaluating and ranking model predictions, but also in training the models themselves.