 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Importance of Adaptive Data Collection for Extremely Imbalanced Pairwise Tasks
Paper and Code
Oct 10, 2020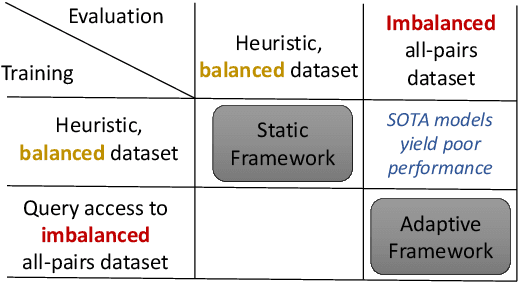
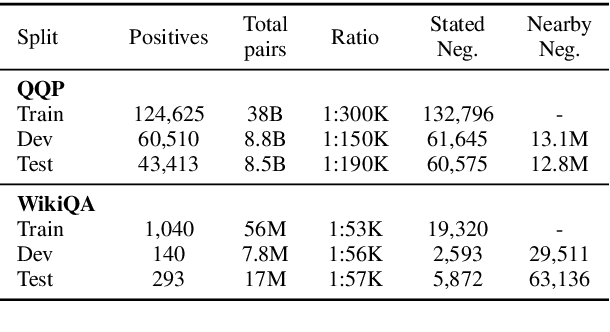
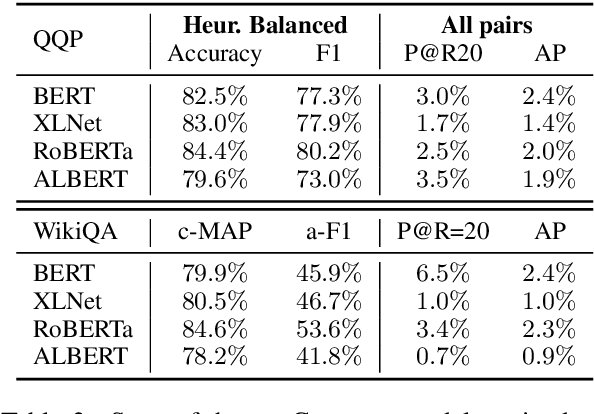
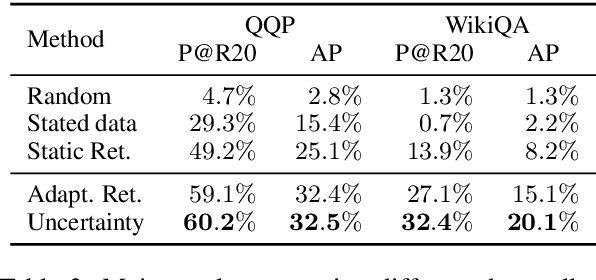
Many pairwise classification tasks, such as paraphrase detection and open-domain question answering, naturally have extreme label imbalance (e.g., $99.99\%$ of examples are negatives). In contrast, many recent datasets heuristically choose examples to ensure label balance. We show that these heuristics lead to trained models that generalize poorly: State-of-the art models trained on QQP and WikiQA each have only $2.4\%$ average precision when evaluated on realistically imbalanced test data. We instead collect training data with active learning, using a BERT-based embedding model to efficiently retrieve uncertain points from a very large pool of unlabeled utterance pairs. By creating balanced training data with more informative negative examples, active learning greatly improves average precision to $32.5\%$ on QQP and $20.1\%$ on WikiQA.