 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproved Techniques for Model Inversion Attacks
Paper and Code
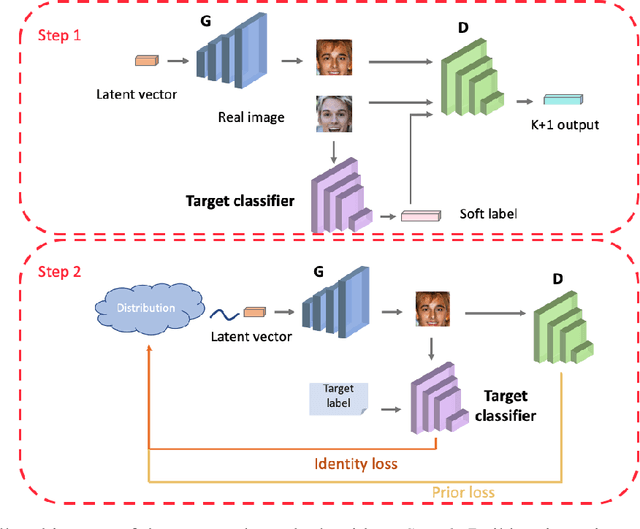

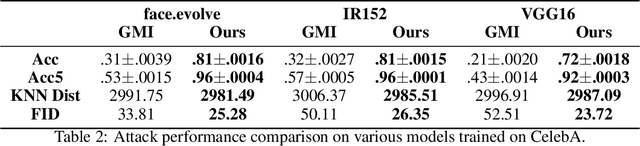

Model inversion (MI) attacks in the whitebox setting are aimed at reconstructing training data from model parameters. Such attacks have triggered increasing concerns about privacy, especially given a growing number of online model repositories. However, existing MI attacks against deep neural networks (DNNs) have large room for performance improvement. A natural question is whether the underperformance is because the target model does not memorize much about its training data or it is simply an artifact of imperfect attack algorithm design? This paper shows that it is the latter. We present a variety of new techniques that can significantly boost the performance of MI attacks against DNNs. Recent advances to attack DNNs are largely attributed to the idea of training a general generative adversarial network (GAN) with potential public data and using it to regularize the search space for reconstructed images. We propose to customize the training of a GAN to the inversion task so as to better distill knowledge useful for performing attacks from public data. Moreover, unlike previous work that directly searches for a single data point to represent a target class, we propose to model private data distribution in order to better reconstruct representative data points. Our experiments show that the combination of these techniques can lead to state-of-the-art attack performance on a variety of datasets and models, even when the public data has a large distributional shift from the private data.