 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWikiLingua: A New Benchmark Dataset for Cross-Lingual Abstractive Summarization
Paper and Code



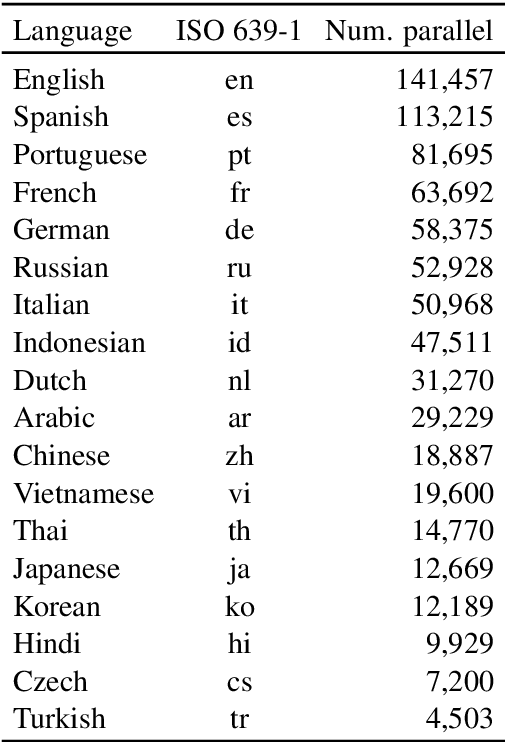
We introduce WikiLingua, a large-scale, multilingual dataset for the evaluation of crosslingual abstractive summarization systems. We extract article and summary pairs in 18 languages from WikiHow, a high quality, collaborative resource of how-to guides on a diverse set of topics written by human authors. We create gold-standard article-summary alignments across languages by aligning the images that are used to describe each how-to step in an article. As a set of baselines for further studies, we evaluate the performance of existing cross-lingual abstractive summarization methods on our dataset. We further propose a method for direct crosslingual summarization (i.e., without requiring translation at inference time) by leveraging synthetic data and Neural Machine Translation as a pre-training step. Our method significantly outperforms the baseline approaches, while being more cost efficient during inference.