 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQADiscourse -- Discourse Relations as QA Pairs: Representation, Crowdsourcing and Baselines
Paper and Code

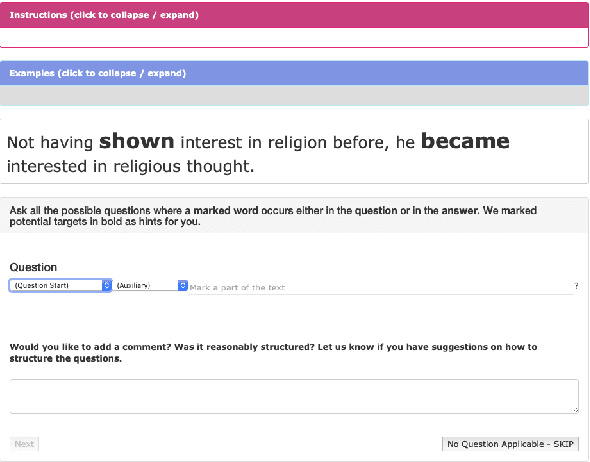

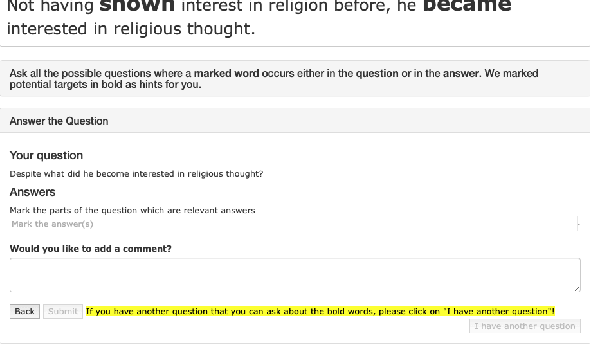
Discourse relations describe how two propositions relate to one another, and identifying them automatically is an integral part of natural language understanding. However, annotating discourse relations typically requires expert annotators. Recently, different semantic aspects of a sentence have been represented and crowd-sourced via question-and-answer (QA) pairs. This paper proposes a novel representation of discourse relations as QA pairs, which in turn allows us to crowd-source wide-coverage data annotated with discourse relations, via an intuitively appealing interface for composing such questions and answers. Based on our proposed representation, we collect a novel and wide-coverage QADiscourse dataset, and present baseline algorithms for predicting QADiscourse relations.