 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Visual-Semantic Embeddings for Reporting Abnormal Findings on Chest X-rays
Paper and Code

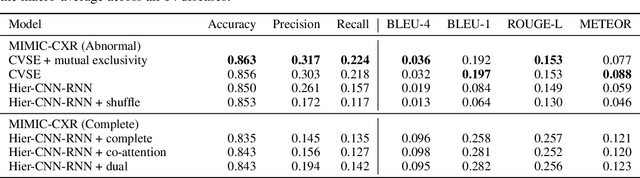
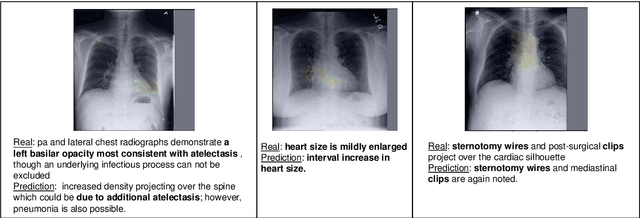
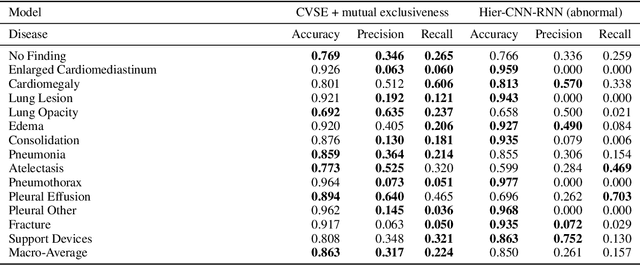
Automatic medical image report generation has drawn growing attention due to its potential to alleviate radiologists' workload. Existing work on report generation often trains encoder-decoder networks to generate complete reports. However, such models are affected by data bias (e.g.~label imbalance) and face common issues inherent in text generation models (e.g.~repetition). In this work, we focus on reporting abnormal findings on radiology images; instead of training on complete radiology reports, we propose a method to identify abnormal findings from the reports in addition to grouping them with unsupervised clustering and minimal rules. We formulate the task as cross-modal retrieval and propose Conditional Visual-Semantic Embeddings to align images and fine-grained abnormal findings in a joint embedding space. We demonstrate that our method is able to retrieve abnormal findings and outperforms existing generation models on both clinical correctness and text generation metrics.