 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Device Directedness Classification of Utterances with Semantic Lexical Features
Paper and Code
Sep 29, 2020
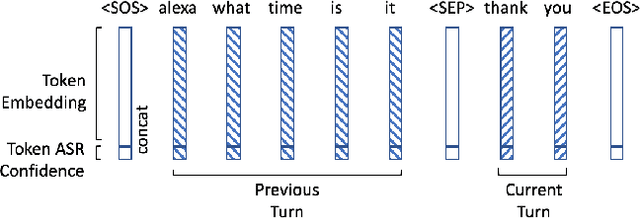

User interactions with personal assistants like Alexa, Google Home and Siri are typically initiated by a wake term or wakeword. Several personal assistants feature "follow-up" modes that allow users to make additional interactions without the need of a wakeword. For the system to only respond when appropriate, and to ignore speech not intended for it, utterances must be classified as device-directed or non-device-directed. State-of-the-art systems have largely used acoustic features for this task, while others have used only lexical features or have added LM-based lexical features. We propose a directedness classifier that combines semantic lexical features with a lightweight acoustic feature and show it is effective in classifying directedness. The mixed-domain lexical and acoustic feature model is able to achieve 14% relative reduction of EER over a state-of-the-art acoustic-only baseline model. Finally, we successfully apply transfer learning and semi-supervised learning to the model to improve accuracy even further.