 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Empirical Investigation Towards Efficient Multi-Domain Language Model Pre-training
Paper and Code
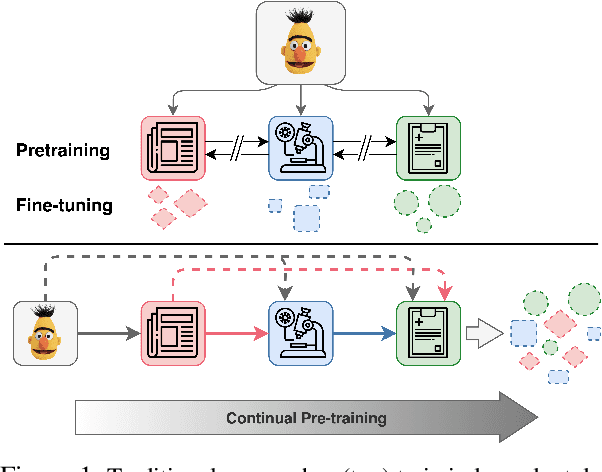
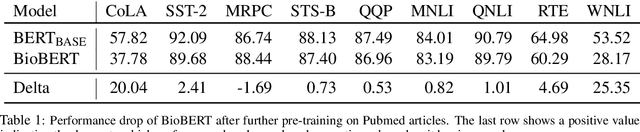
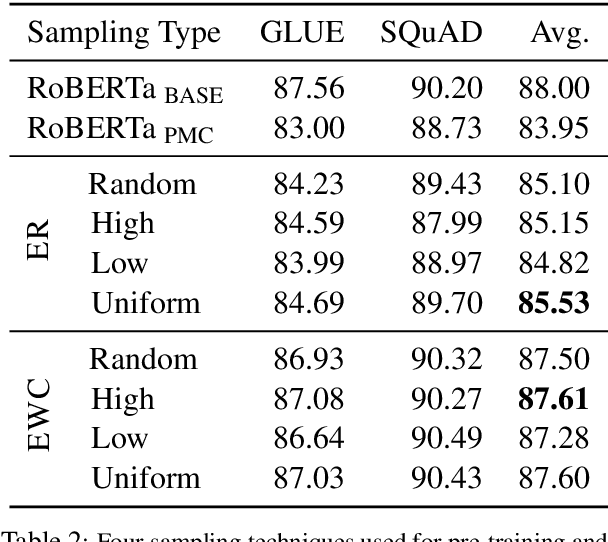
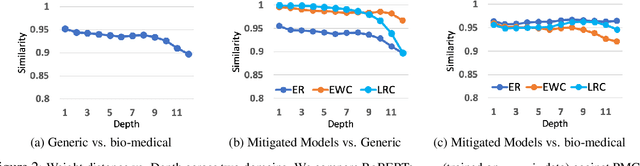
Pre-training large language models has become a standard in the natural language processing community. Such models are pre-trained on generic data (e.g. BookCorpus and English Wikipedia) and often fine-tuned on tasks in the same domain. However, in order to achieve state-of-the-art performance on out of domain tasks such as clinical named entity recognition and relation extraction, additional in domain pre-training is required. In practice, staged multi-domain pre-training presents performance deterioration in the form of catastrophic forgetting (CF) when evaluated on a generic benchmark such as GLUE. In this paper we conduct an empirical investigation into known methods to mitigate CF. We find that elastic weight consolidation provides best overall scores yielding only a 0.33% drop in performance across seven generic tasks while remaining competitive in bio-medical tasks. Furthermore, we explore gradient and latent clustering based data selection techniques to improve coverage when using elastic weight consolidation and experience replay methods.