 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXDA: Accurate, Robust Disassembly with Transfer Learning
Paper and Code
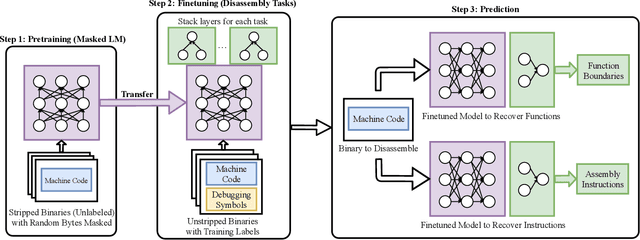
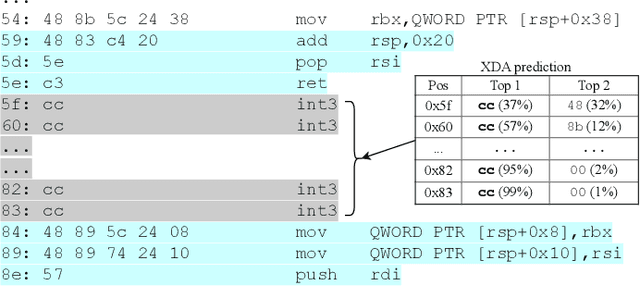
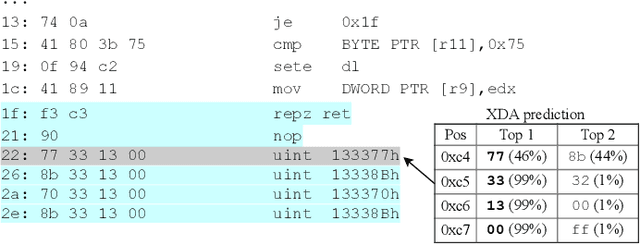
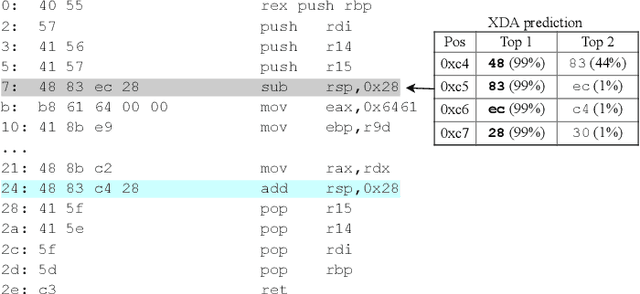
Accurate and robust disassembly of stripped binaries is challenging. The root of the difficulty is that high-level structures, such as instruction and function boundaries, are absent in stripped binaries and must be recovered based on incomplete information. Current disassembly approaches rely on heuristics or simple pattern matching to approximate the recovery, but these methods are often inaccurate and brittle, especially across different compiler optimizations. We present XDA, a transfer-learning-based disassembly framework that learns different contextual dependencies present in machine code and transfers this knowledge for accurate and robust disassembly. We design a self-supervised learning task motivated by masked Language Modeling to learn interactions among byte sequences in binaries. The outputs from this task are byte embeddings that encode sophisticated contextual dependencies between input binaries' byte tokens, which can then be finetuned for downstream disassembly tasks. We evaluate XDA's performance on two disassembly tasks, recovering function boundaries and assembly instructions, on a collection of 3,121 binaries taken from SPEC CPU2017, SPEC CPU2006, and the BAP corpus. The binaries are compiled by GCC, ICC, and MSVC on x86/x64 Windows and Linux platforms over 4 optimization levels. XDA achieves 99.0% and 99.7% F1 score at recovering function boundaries and instructions, respectively, surpassing the previous state-of-the-art on both tasks. It also maintains speed on par with the fastest ML-based approach and is up to 38x faster than hand-written disassemblers like IDA Pro.