Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgnostic Learning of Halfspaces with Gradient Descent via Soft Margins
Paper and Code
Oct 01, 2020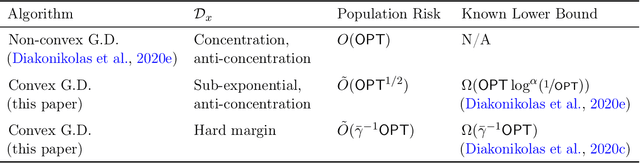
We analyze the properties of gradient descent on convex surrogates for the zero-one loss for the agnostic learning of linear halfspaces. If $\mathsf{OPT}$ is the best classification error achieved by a halfspace, by appealing to the notion of soft margins we are able to show that gradient descent finds halfspaces with classification error $\tilde O(\mathsf{OPT}^{1/2}) + \varepsilon$ in $\mathrm{poly}(d,1/\varepsilon)$ time and sample complexity for a broad class of distributions that includes log-concave isotropic distributions as a subclass. Along the way we answer a question recently posed by Ji et al. (2020) on how the tail behavior of a loss function can affect sample complexity and runtime guarantees for gradient descent.
* 24 pages, 1 table
View paper on