 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep discriminant analysis for task-dependent compact network search
Paper and Code
Sep 29, 2020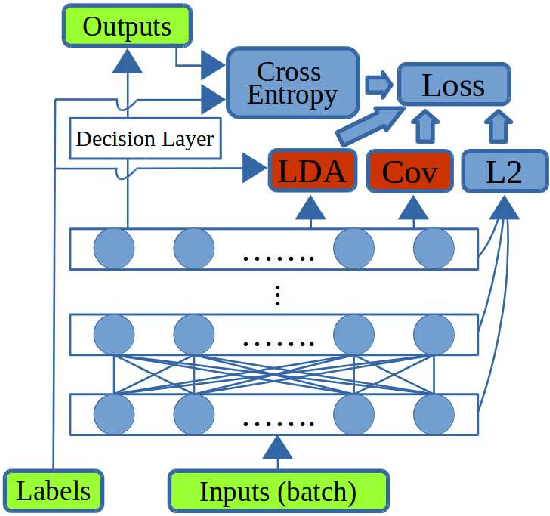
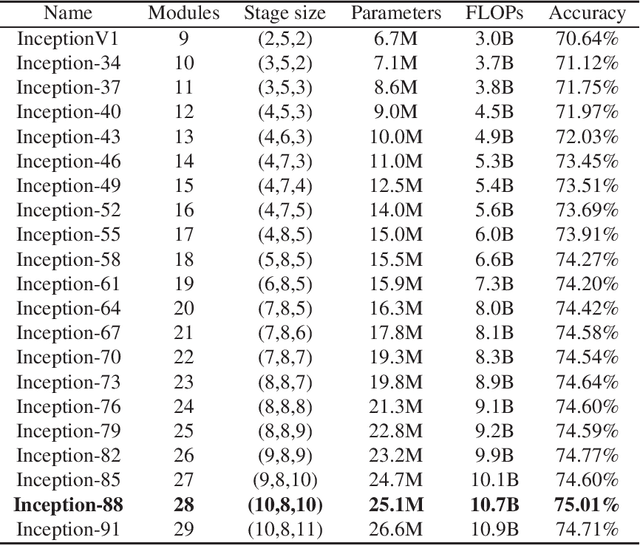
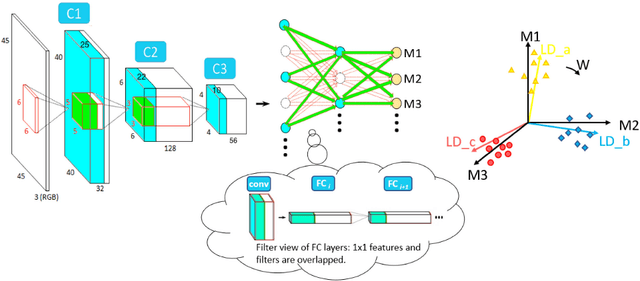
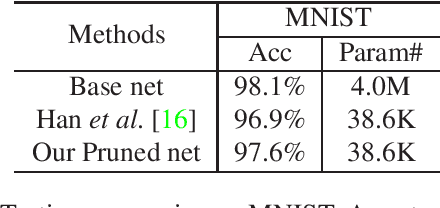
Most of today's popular deep architectures are hand-engineered for general purpose applications. However, this design procedure usually leads to massive redundant, useless, or even harmful features for specific tasks. Such unnecessarily high complexities render deep nets impractical for many real-world applications, especially those without powerful GPU support. In this paper, we attempt to derive task-dependent compact models from a deep discriminant analysis perspective. We propose an iterative and proactive approach for classification tasks which alternates between (1) a pushing step, with an objective to simultaneously maximize class separation, penalize co-variances, and push deep discriminants into alignment with a compact set of neurons, and (2) a pruning step, which discards less useful or even interfering neurons. Deconvolution is adopted to reverse `unimportant' filters' effects and recover useful contributing sources. A simple network growing strategy based on the basic Inception module is proposed for challenging tasks requiring larger capacity than what the base net can offer. Experiments on the MNIST, CIFAR10, and ImageNet datasets demonstrate our approach's efficacy. On ImageNet, by pushing and pruning our grown Inception-88 model, we achieve better-performing models than smaller deep Inception nets grown, residual nets, and famous compact nets at similar sizes. We also show that our grown deep Inception nets (without hard-coded dimension alignment) can beat residual nets of similar complexities.