 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Model Adaptation for Continual Semantic Segmentation
Paper and Code
Sep 26, 2020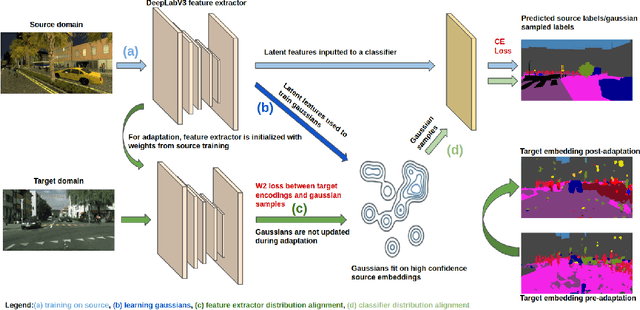
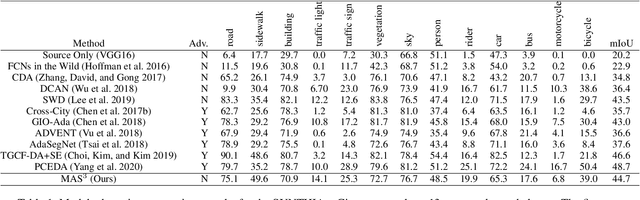
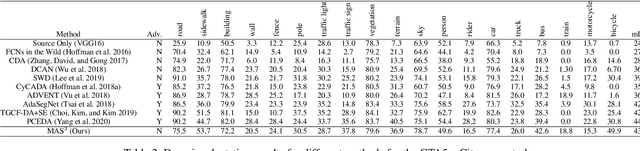
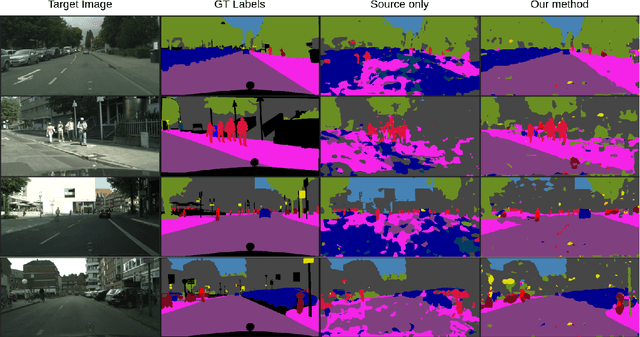
We develop an algorithm for adapting a semantic segmentation model that is trained using a labeled source domain to generalize well in an unlabeled target domain. A similar problem has been studied extensively in the unsupervised domain adaptation (UDA) literature, but existing UDA algorithms require access to both the source domain labeled data and the target domain unlabeled data for training a domain agnostic semantic segmentation model. Relaxing this constraint enables a user to adapt pretrained models to generalize in a target domain, without requiring access to source data. To this end, we learn a prototypical distribution for the source domain in an intermediate embedding space. This distribution encodes the abstract knowledge that is learned from the source domain. We then use this distribution for aligning the target domain distribution with the source domain distribution in the embedding space. We provide theoretical analysis and explain conditions under which our algorithm is effective. Experiments on benchmark adaptation task demonstrate our method achieves competitive performance even compared with joint UDA approaches.