 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrame-wise Cross-modal Match for Video Moment Retrieval
Paper and Code

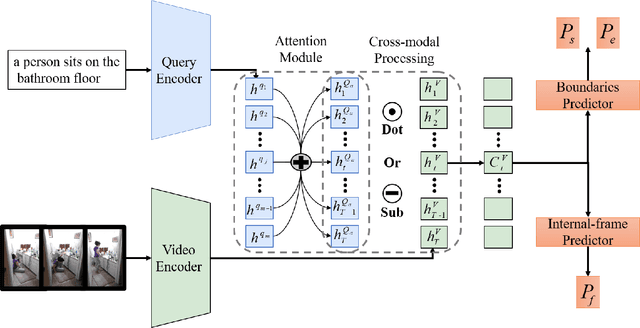

Video moment retrieval targets at retrieving a golden moment in a video for a given natural language query. The main challenges of this task include 1) the requirement of accurately localizing (i.e., the start time and the end time of) the relevant moment in an untrimmed video stream, and 2) bridging the semantic gap between textual query and video contents. To tackle those problems, One mainstream approach is to generate a multimodal feature vector for the target query and video frames (e.g., concatenation) and then use a regression approach upon the multimodal feature vector for boundary detection. Although some progress has been achieved by this approach, we argue that those methods have not well captured the cross-modal interactions between the query and video frames. In this paper, we propose an Attentive Cross-modal Relevance Matching (ACRM) model which predicts the temporal bounders based on an interaction modeling between two modalities. In addition, an attention module is introduced to automatically assign higher weights to query words with richer semantic cues, which are considered to be more important for finding relevant video contents. Another contribution is that we propose an additional predictor to utilize the internal frames in the model training to improve the localization accuracy. Extensive experiments on two public datasetsdemonstrate the superiority of our method over several state-of-the-art methods.