 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFaster Gradient-based NAS Pipeline Combining Broad Scalable Architecture with Confident Learning Rate
Paper and Code
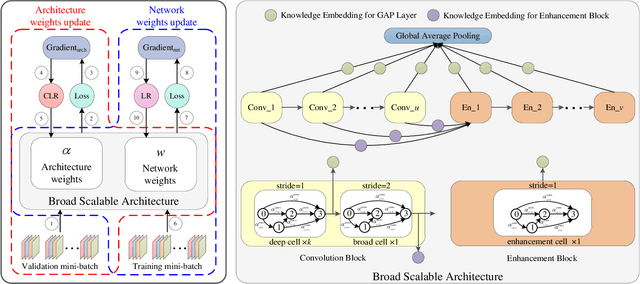
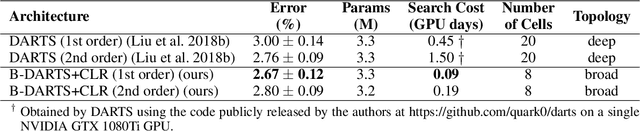
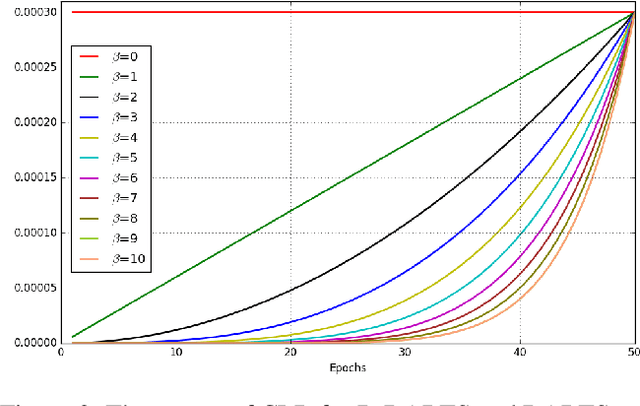
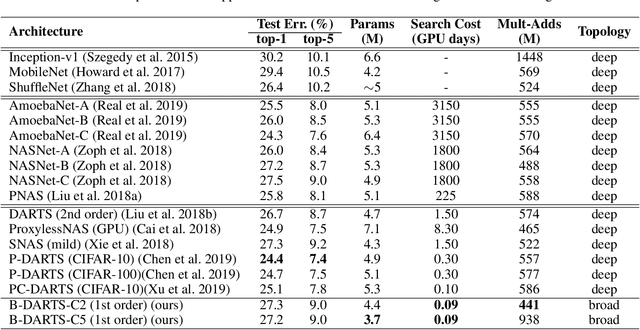
In order to further improve the search efficiency of Neural Architecture Search (NAS), we propose B-DARTS, a novel pipeline combining broad scalable architecture with Confident Learning Rate (CLR). In B-DARTS, Broad Convolutional Neural Network (BCNN) is employed as the scalable architecture for DARTS, a popular differentiable NAS approach. On one hand, BCNN is a broad scalable architecture whose topology achieves two advantages compared with the deep one, mainly including faster single-step training speed and higher memory efficiency (i.e. larger batch size for architecture search), which are all contributed to the search efficiency improvement of NAS. On the other hand, DARTS discovers the optimal architecture by gradient-based optimization algorithm, which benefits from two superiorities of BCNN simultaneously. Similar to vanilla DARTS, B-DARTS also suffers from the performance collapse issue, where those weight-free operations are prone to be selected by the search strategy. Therefore, we propose CLR, that considers the confidence of gradient for architecture weights update increasing with the training time of over-parameterized model, to mitigate the above issue. Experimental results on CIFAR-10 and ImageNet show that 1) B-DARTS delivers state-of-the-art efficiency of 0.09 GPU day using first order approximation on CIFAR-10; 2) the learned architecture by B-DARTS achieves competitive performance using state-of-the-art composite multiply-accumulate operations and parameters on ImageNet; and 3) the proposed CLR is effective for performance collapse issue alleviation of both B-DARTS and DARTS.