 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Transferability of Minimal Prediction Preserving Inputs in Question Answering
Paper and Code
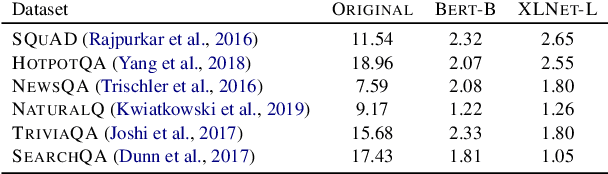
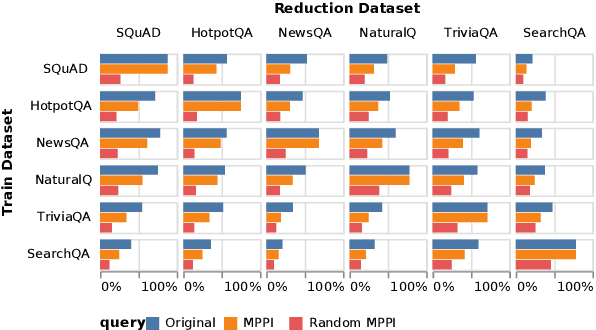


Recent work (Feng et al., 2018) establishes the presence of short, uninterpretable input fragments that yield high confidence and accuracy in neural models. We refer to these as Minimal Prediction Preserving Inputs (MPPIs). In the context of question answering, we investigate competing hypotheses for the existence of MPPIs, including poor posterior calibration of neural models, lack of pretraining, and "dataset bias" (where a model learns to attend to spurious, non-generalizable cues in the training data). We discover a perplexing invariance of MPPIs to random training seed, model architecture, pretraining, and training domain. MPPIs demonstrate remarkable transferability across domains - closing half the gap between models' performance on comparably short queries and original queries. Additionally, penalizing over-confidence on MPPIs fails to improve either generalization or adversarial robustness. These results suggest the interpretability of MPPIs is insufficient to characterize generalization capacity of these models. We hope this focused investigation encourages a more systematic analysis of model behavior outside of the human interpretable distribution of examples.