 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Self-Supervised Pretraining Without Using Labels
Paper and Code
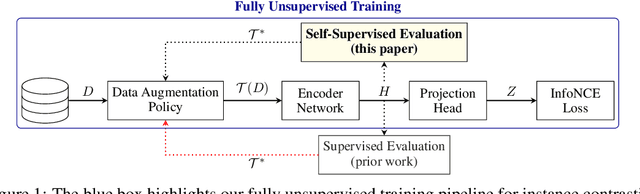
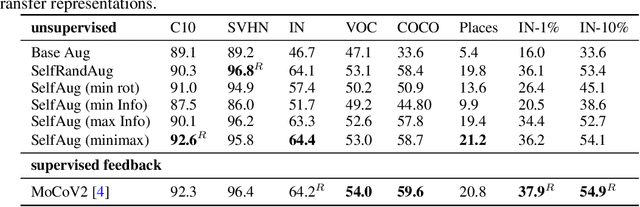
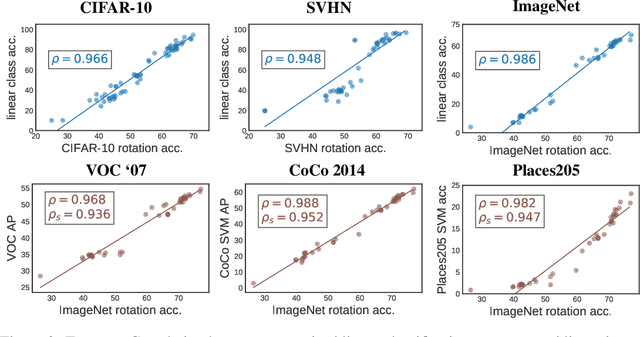
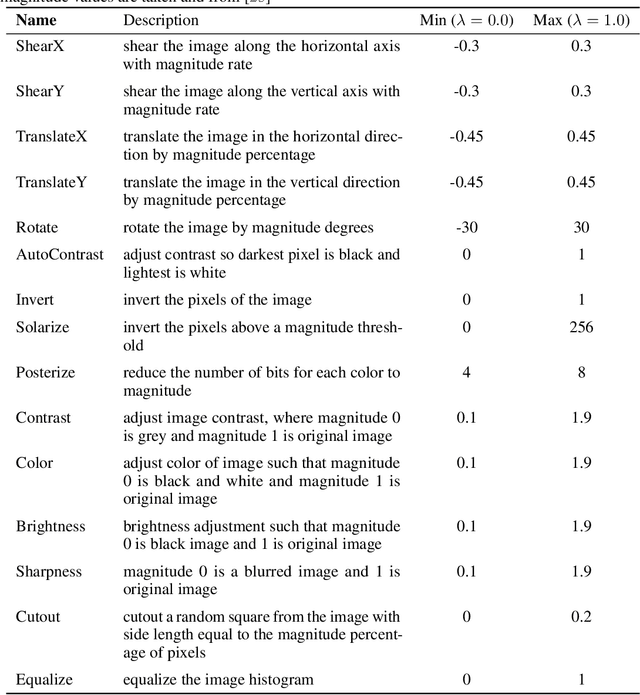
A common practice in unsupervised representation learning is to use labeled data to evaluate the learned representations - oftentimes using the labels from the "unlabeled" training dataset. This supervised evaluation is then used to guide the training process, e.g. to select augmentation policies. However, supervised evaluations may not be possible when labeled data is difficult to obtain (such as medical imaging) or ambiguous to label (such as fashion categorization). This raises the question: is it possible to evaluate unsupervised models without using labeled data? Furthermore, is it possible to use this evaluation to make decisions about the training process, such as which augmentation policies to use? In this work, we show that the simple self-supervised evaluation task of image rotation prediction is highly correlated with the supervised performance of standard visual recognition tasks and datasets (rank correlation > 0.94). We establish this correlation across hundreds of augmentation policies and training schedules and show how this evaluation criteria can be used to automatically select augmentation policies without using labels. Despite not using any labeled data, these policies perform comparably with policies that were determined using supervised downstream tasks. Importantly, this work explores the idea of using unsupervised evaluation criteria to help both researchers and practitioners make decisions when training without labeled data.