 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Principled Approach to Data Valuation for Federated Learning
Paper and Code
Sep 14, 2020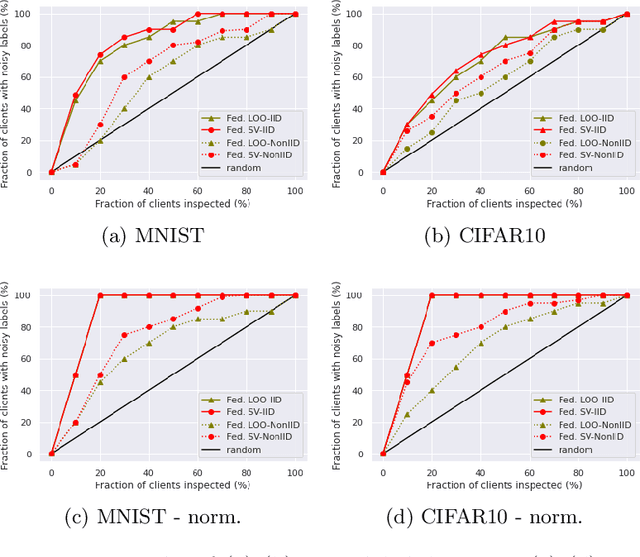

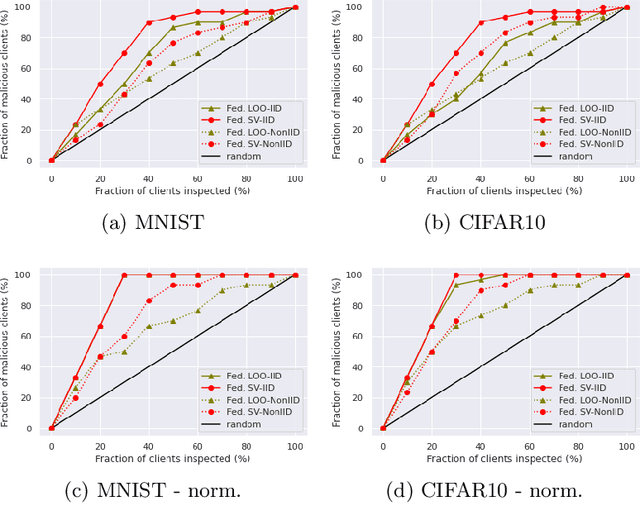
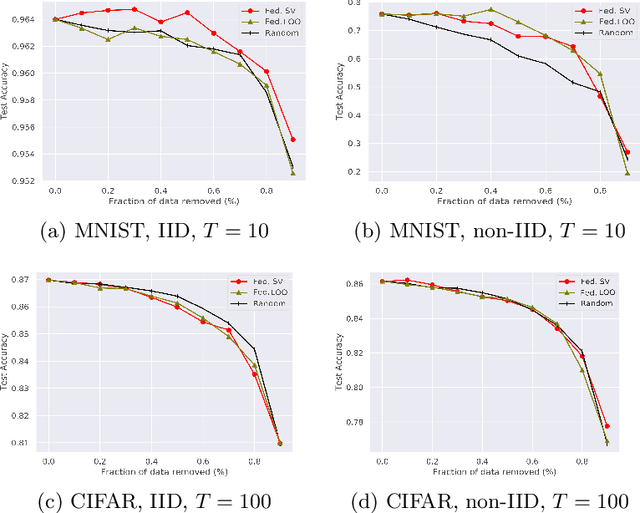
Federated learning (FL) is a popular technique to train machine learning (ML) models on decentralized data sources. In order to sustain long-term participation of data owners, it is important to fairly appraise each data source and compensate data owners for their contribution to the training process. The Shapley value (SV) defines a unique payoff scheme that satisfies many desiderata for a data value notion. It has been increasingly used for valuing training data in centralized learning. However, computing the SV requires exhaustively evaluating the model performance on every subset of data sources, which incurs prohibitive communication cost in the federated setting. Besides, the canonical SV ignores the order of data sources during training, which conflicts with the sequential nature of FL. This paper proposes a variant of the SV amenable to FL, which we call the federated Shapley value. The federated SV preserves the desirable properties of the canonical SV while it can be calculated without incurring extra communication cost and is also able to capture the effect of participation order on data value. We conduct a thorough empirical study of the federated SV on a range of tasks, including noisy label detection, adversarial participant detection, and data summarization on different benchmark datasets, and demonstrate that it can reflect the real utility of data sources for FL and has the potential to enhance system robustness, security, and efficiency. We also report and analyze "failure cases" and hope to stimulate future research.