 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic-preserving Reinforcement Learning Attack Against Graph Neural Networks for Malware Detection
Paper and Code


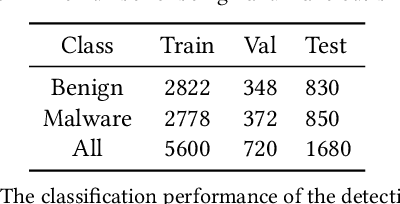
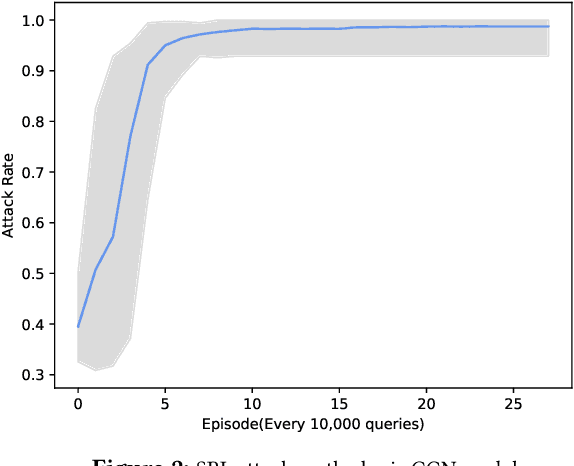
To address the costs of reverse engineering and signature extraction, advanced research on malware detection focuses on using neural networks to learn malicious behaviors with static and dynamic features. However, deep learning-based malware detection models are vulnerable to a hack from adversarial samples. The attackers' goal is to generate imperceptible perturbations to the original samples and evade detection. In the context of malware, the generated samples should have one more important character: it should not change the malicious behaviors of the original code. So the original features can not be removed and changed. In this paper, we proposed a reinforcement learning based attack to deceive graph based malware detection models. Inspired by obfuscation techniques, the central idea of the proposed attack is to sequentially inject semantic Nops, which will not change the program's functionality, into CFGs(Control Flow Graph). Specifically, the Semantics-preserving Reinforcement Learning(SRL) Attack is to learn an RL agent to iteratively select the semantic Nops and insert them into basic blocks of the CFGs. Variants of obfuscation methods, hill-climbing methods, and gradient based algorithms are proposed: 1) Semantics-preserving Random Insertion(SRI) Attack: randomly inserting semantic Nops into basic blocks.; 2) Semantics-preserving Accumulated Insertion(SAI) Attack: declining certain random transformation according to the probability of the target class; 3) Semantics-preserving Gradient based Insertion(SGI) Attack: applying transformation on the original CFG in the direction of the gradient. We use real-world Windows programs to show that a family of Graph Neural Network models are vulnerable to these attacks. The best evasion rate of the benchmark attacks are 97% on the basic GCN model and 96% on DGCNN model. The SRL attack can achieve 100% on both models.