 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRadLex Normalization in Radiology Reports
Paper and Code
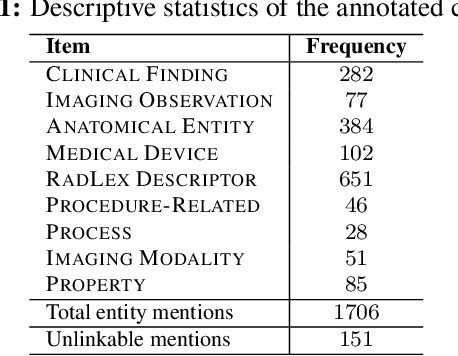
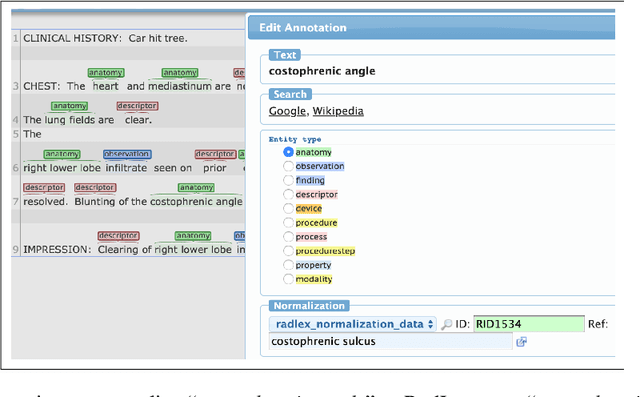
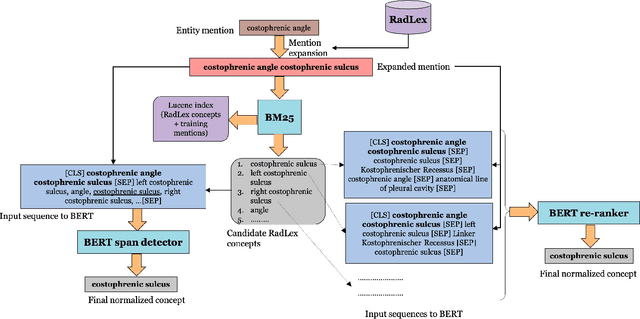

Radiology reports have been widely used for extraction of various clinically significant information about patients' imaging studies. However, limited research has focused on standardizing the entities to a common radiology-specific vocabulary. Further, no study to date has attempted to leverage RadLex for standardization. In this paper, we aim to normalize a diverse set of radiological entities to RadLex terms. We manually construct a normalization corpus by annotating entities from three types of reports. This contains 1706 entity mentions. We propose two deep learning-based NLP methods based on a pre-trained language model (BERT) for automatic normalization. First, we employ BM25 to retrieve candidate concepts for the BERT-based models (re-ranker and span detector) to predict the normalized concept. The results are promising, with the best accuracy (78.44%) obtained by the span detector. Additionally, we discuss the challenges involved in corpus construction and propose new RadLex terms.