 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmotion-Based End-to-End Matching Between Image and Music in Valence-Arousal Space
Paper and Code
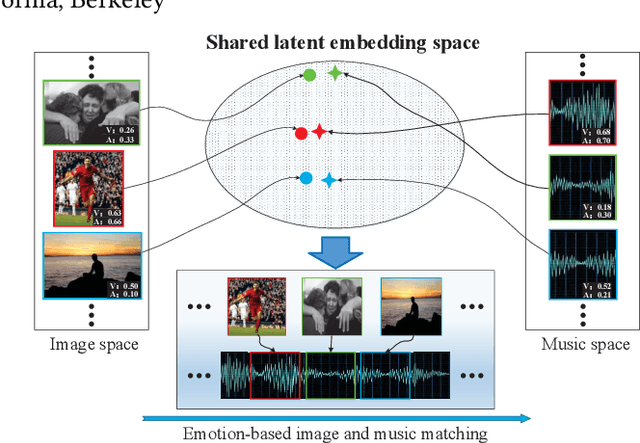
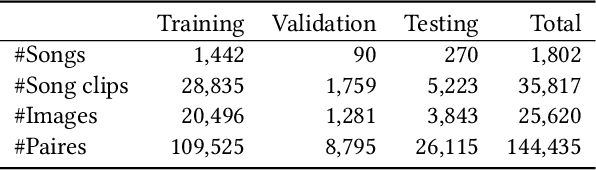
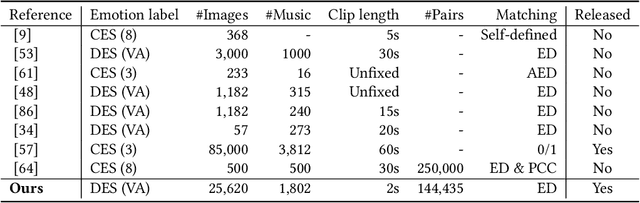
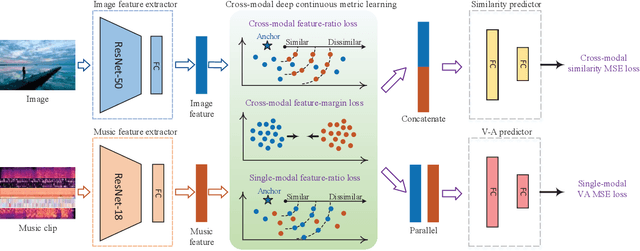
Both images and music can convey rich semantics and are widely used to induce specific emotions. Matching images and music with similar emotions might help to make emotion perceptions more vivid and stronger. Existing emotion-based image and music matching methods either employ limited categorical emotion states which cannot well reflect the complexity and subtlety of emotions, or train the matching model using an impractical multi-stage pipeline. In this paper, we study end-to-end matching between image and music based on emotions in the continuous valence-arousal (VA) space. First, we construct a large-scale dataset, termed Image-Music-Emotion-Matching-Net (IMEMNet), with over 140K image-music pairs. Second, we propose cross-modal deep continuous metric learning (CDCML) to learn a shared latent embedding space which preserves the cross-modal similarity relationship in the continuous matching space. Finally, we refine the embedding space by further preserving the single-modal emotion relationship in the VA spaces of both images and music. The metric learning in the embedding space and task regression in the label space are jointly optimized for both cross-modal matching and single-modal VA prediction. The extensive experiments conducted on IMEMNet demonstrate the superiority of CDCML for emotion-based image and music matching as compared to the state-of-the-art approaches.