 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMassively Parallel and Asynchronous Tsetlin Machine Architecture Supporting Almost Constant-Time Scaling
Paper and Code
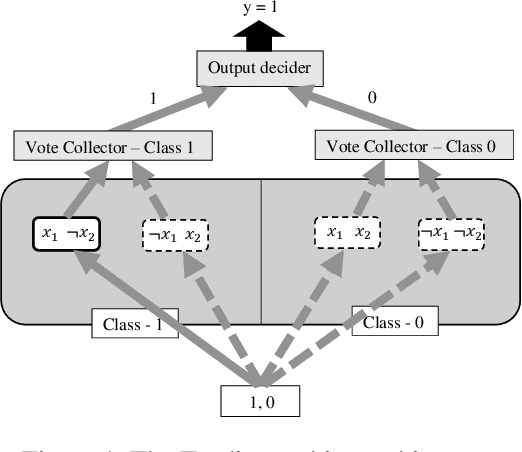
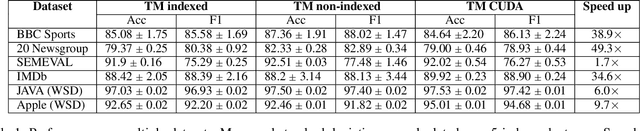
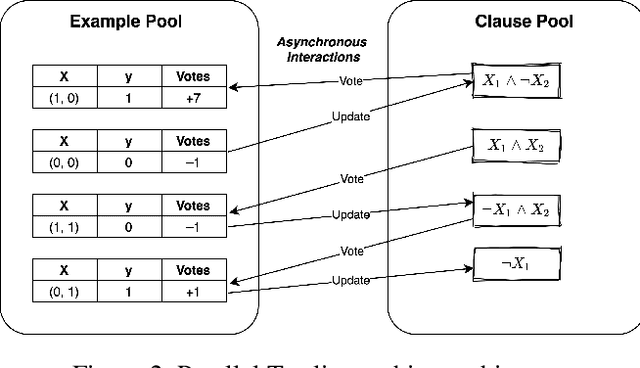
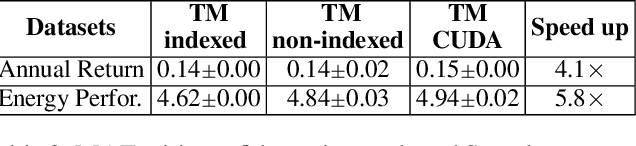
Using logical clauses to represent patterns, Tsetlin machines (TMs) have recently obtained competitive performance in terms of accuracy, memory footprint, energy, and learning speed on several benchmarks. A team of Tsetlin automata (TAs) composes each clause, thus driving the entire learning process. These are rewarded/penalized according to three local rules that optimize global behaviour. Each clause votes for or against a particular class, with classification resolved using a majority vote. In the parallel and asynchronous architecture that we propose here, every clause runs in its own thread for massive parallelism. For each training example, we keep track of the class votes obtained from the clauses in local voting tallies. The local voting tallies allow us to detach the processing of each clause from the rest of the clauses, supporting decentralized learning. Thus, rather than processing training examples one-by-one as in the original TM, the clauses access the training examples simultaneously, updating themselves and the local voting tallies in parallel. There is no synchronization among the clause threads, apart from atomic adds to the local voting tallies. Operating asynchronously, each team of TA will most of the time operate on partially calculated or outdated voting tallies. However, across diverse learning tasks, it turns out that our decentralized TM learning algorithm copes well with working on outdated data, resulting in no significant loss in learning accuracy. Further, we show that the approach provides up to 50 times faster learning. Finally, learning time is almost constant for reasonable clause amounts. For sufficiently large clause numbers, computation time increases approximately proportionally. Our parallel and asynchronous architecture thus allows processing of more massive datasets and operating with more clauses for higher accuracy.