 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTunable Subnetwork Splitting for Model-parallelism of Neural Network Training
Paper and Code
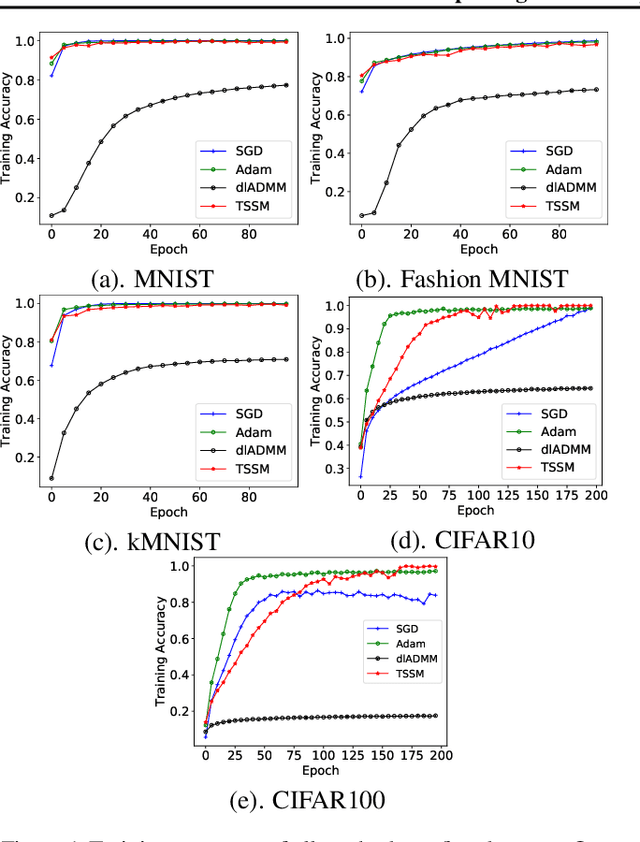
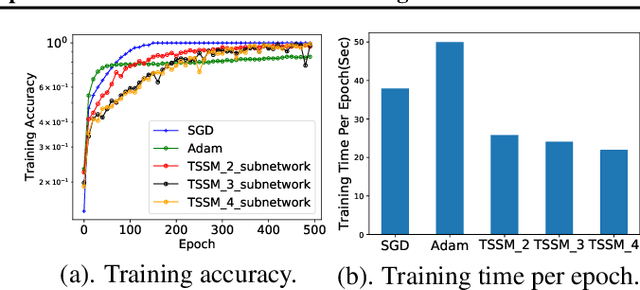
Alternating minimization methods have recently been proposed as alternatives to the gradient descent for deep neural network optimization. Alternating minimization methods can typically decompose a deep neural network into layerwise subproblems, which can then be optimized in parallel. Despite the significant parallelism, alternating minimization methods are rarely explored in training deep neural networks because of the severe accuracy degradation. In this paper, we analyze the reason and propose to achieve a compelling trade-off between parallelism and accuracy by a reformulation called Tunable Subnetwork Splitting Method (TSSM), which can tune the decomposition granularity of deep neural networks. Two methods gradient splitting Alternating Direction Method of Multipliers (gsADMM) and gradient splitting Alternating Minimization (gsAM) are proposed to solve the TSSM formulation. Experiments on five benchmark datasets show that our proposed TSSM can achieve significant speedup without observable loss of training accuracy. The code has been released at https://github.com/xianggebenben/TSSM.