 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSEANet: A Multi-modal Speech Enhancement Network
Paper and Code
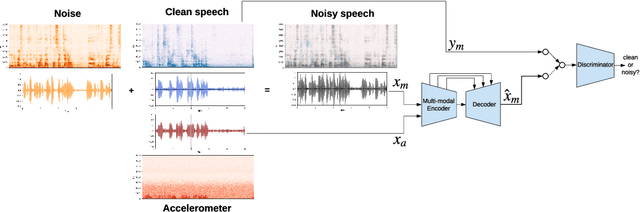
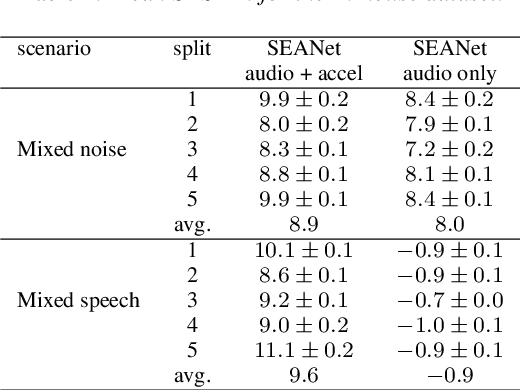
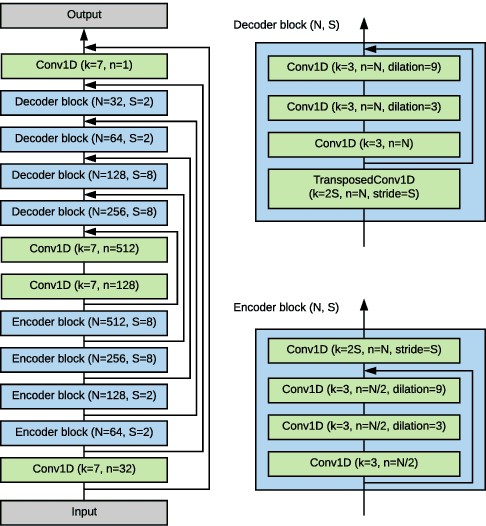

We explore the possibility of leveraging accelerometer data to perform speech enhancement in very noisy conditions. Although it is possible to only partially reconstruct user's speech from the accelerometer, the latter provides a strong conditioning signal that is not influenced from noise sources in the environment. Based on this observation, we feed a multi-modal input to SEANet (Sound EnhAncement Network), a wave-to-wave fully convolutional model, which adopts a combination of feature losses and adversarial losses to reconstruct an enhanced version of user's speech. We trained our model with data collected by sensors mounted on an earbud and synthetically corrupted by adding different kinds of noise sources to the audio signal. Our experimental results demonstrate that it is possible to achieve very high quality results, even in the case of interfering speech at the same level of loudness. A sample of the output produced by our model is available at https://google-research.github.io/seanet/multimodal/speech.