 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMixBoost: Synthetic Oversampling with Boosted Mixup for Handling Extreme Imbalance
Paper and Code
Sep 03, 2020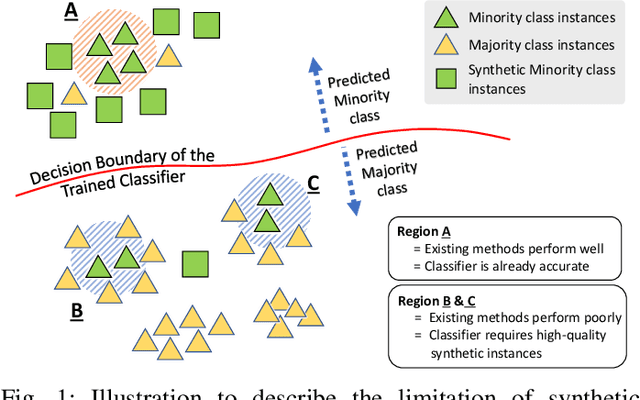
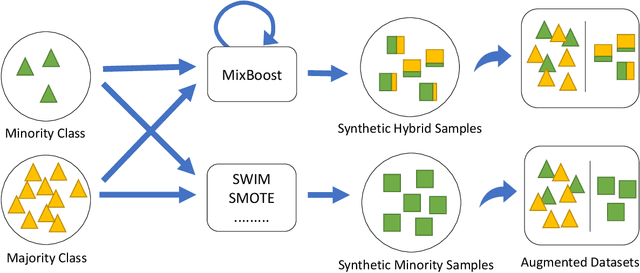
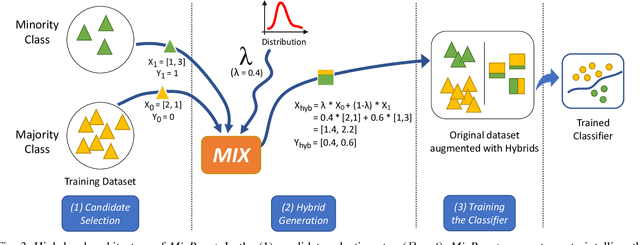
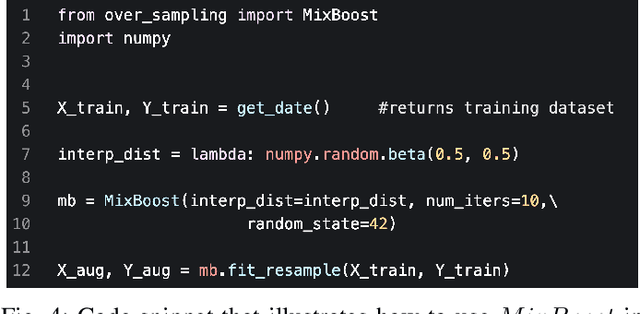
Training a classification model on a dataset where the instances of one class outnumber those of the other class is a challenging problem. Such imbalanced datasets are standard in real-world situations such as fraud detection, medical diagnosis, and computational advertising. We propose an iterative data augmentation method, MixBoost, which intelligently selects (Boost) and then combines (Mix) instances from the majority and minority classes to generate synthetic hybrid instances that have characteristics of both classes. We evaluate MixBoost on 20 benchmark datasets, show that it outperforms existing approaches, and test its efficacy through significance testing. We also present ablation studies to analyze the impact of the different components of MixBoost.