 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Demystifying Dimensions of Source Code Embeddings
Paper and Code
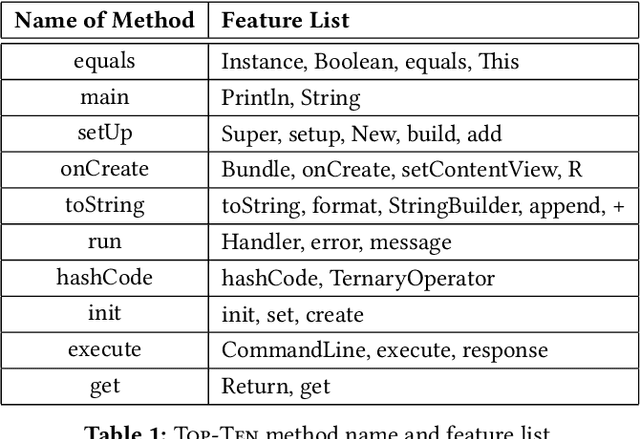

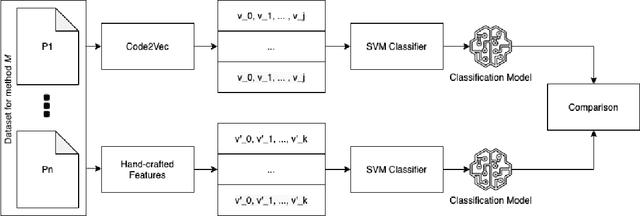
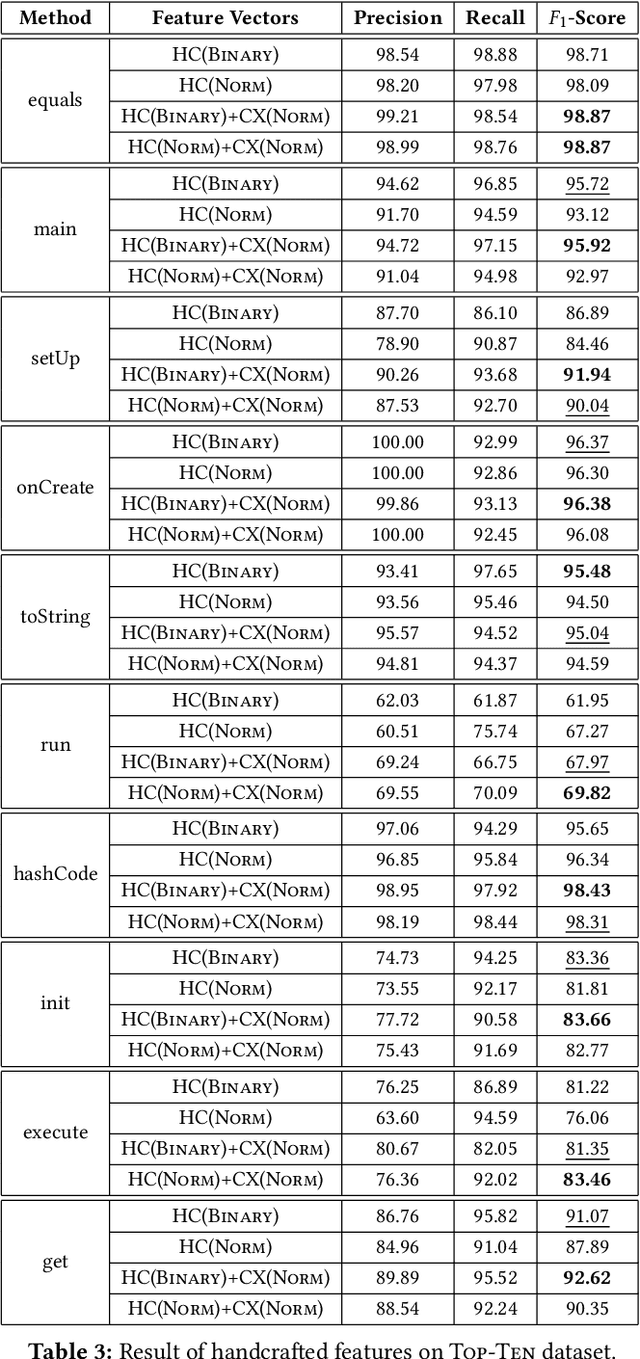
Source code representations are key in applying machine learning techniques for processing and analyzing programs. A popular approach in representing source code is neural source code embeddings that represents programs with high-dimensional vectors computed by training deep neural networks on a large volume of programs. Although successful, there is little known about the contents of these vectors and their characteristics. In this paper, we present our preliminary results towards better understanding the contents of code2vec neural source code embeddings. In particular, in a small case study, we use the code2vec embeddings to create binary SVM classifiers and compare their performance with the handcrafted features. Our results suggest that the handcrafted features can perform very close to the highly-dimensional code2vec embeddings, and the information gains are more evenly distributed in the code2vec embeddings compared to the handcrafted features. We also find that the code2vec embeddings are more resilient to the removal of dimensions with low information gains than the handcrafted features. We hope our results serve a stepping stone toward principled analysis and evaluation of these code representations.