 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePollux: Co-adaptive Cluster Scheduling for Goodput-Optimized Deep Learning
Paper and Code
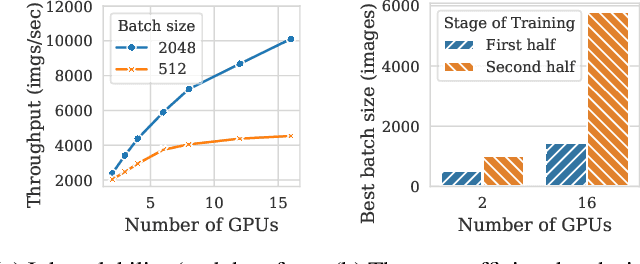

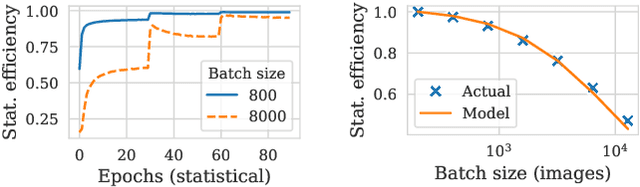
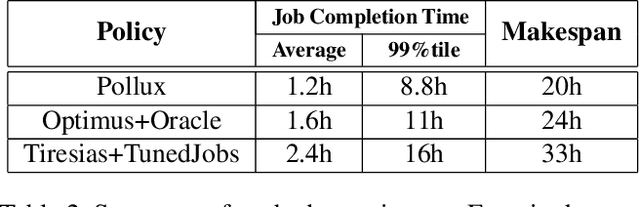
Pollux improves scheduling performance in deep learning (DL) clusters by adaptively co-optimizing inter-dependent factors both at the per-job level and at the cluster-wide level. Most existing schedulers will assign each job a number of resources requested by the user, which can allow jobs to use those resources inefficiently. Some recent schedulers choose job resources for users, but do so without awareness of how DL training can be re-optimized to better utilize those resources. Pollux simultaneously considers both aspects. By observing each job during training, Pollux models how their goodput (system throughput combined with statistical efficiency) would change by adding or removing resources. Leveraging these models, Pollux dynamically (re-)assigns resources to maximize cluster-wide goodput, while continually optimizing each DL job to better utilize those resources. In experiments with real DL training jobs and with trace-driven simulations, Pollux reduces average job completion time by 25%-50% relative to state-of-the-art DL schedulers, even when all jobs are submitted with ideal resource and training configurations. Based on the observation that the statistical efficiency of DL training can change over time, we also show that Pollux can reduce the cost of training large models in cloud environments by 25%.