 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Serverless Learning
Paper and Code
Aug 24, 2020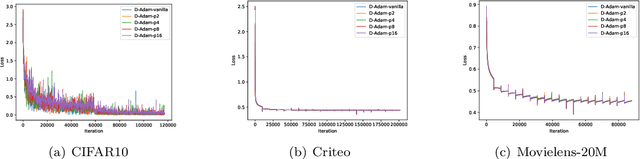
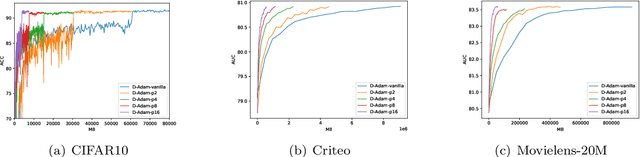
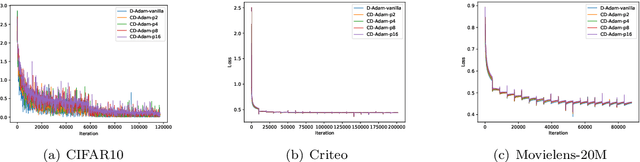
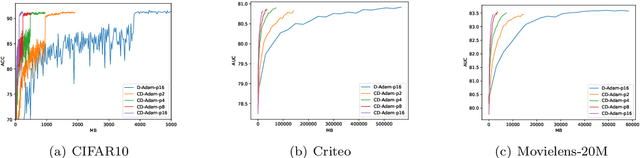
With the emergence of distributed data, training machine learning models in the serverless manner has attracted increasing attention in recent years. Numerous training approaches have been proposed in this regime, such as decentralized SGD. However, all existing decentralized algorithms only focus on standard SGD. It might not be suitable for some applications, such as deep factorization machine in which the feature is highly sparse and categorical so that the adaptive training algorithm is needed. In this paper, we propose a novel adaptive decentralized training approach, which can compute the learning rate from data dynamically. To the best of our knowledge, this is the first adaptive decentralized training approach. Our theoretical results reveal that the proposed algorithm can achieve linear speedup with respect to the number of workers. Moreover, to reduce the communication-efficient overhead, we further propose a communication-efficient adaptive decentralized training approach, which can also achieve linear speedup with respect to the number of workers. At last, extensive experiments on different tasks have confirmed the effectiveness of our proposed two approaches.