 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Case for Learned Spatial Indexes
Paper and Code
Aug 24, 2020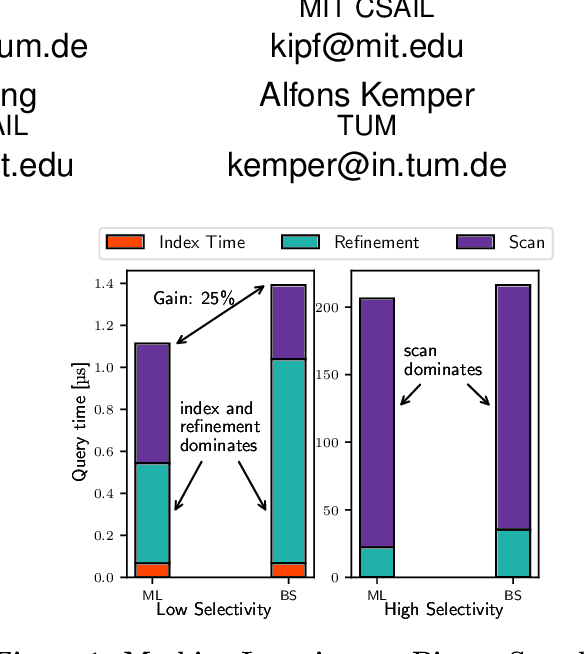
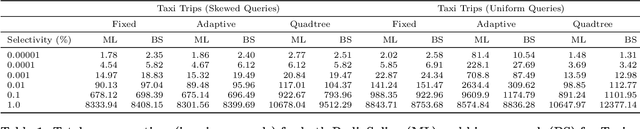

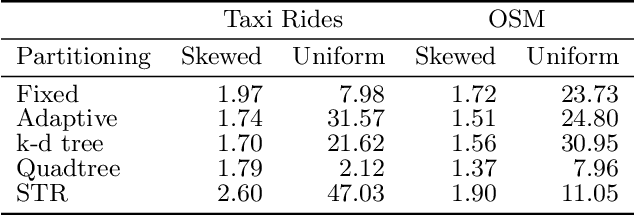
Spatial data is ubiquitous. Massive amounts of data are generated every day from billions of GPS-enabled devices such as cell phones, cars, sensors, and various consumer-based applications such as Uber, Tinder, location-tagged posts in Facebook, Twitter, Instagram, etc. This exponential growth in spatial data has led the research community to focus on building systems and applications that can process spatial data efficiently. In the meantime, recent research has introduced learned index structures. In this work, we use techniques proposed from a state-of-the art learned multi-dimensional index structure (namely, Flood) and apply them to five classical multi-dimensional indexes to be able to answer spatial range queries. By tuning each partitioning technique for optimal performance, we show that (i) machine learned search within a partition is faster by 11.79\% to 39.51\% than binary search when using filtering on one dimension, (ii) the bottleneck for tree structures is index lookup, which could potentially be improved by linearizing the indexed partitions (iii) filtering on one dimension and refining using machine learned indexes is 1.23x to 1.83x times faster than closest competitor which filters on two dimensions, and (iv) learned indexes can have a significant impact on the performance of low selectivity queries while being less effective under higher selectivities.