 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMTOP: A Comprehensive Multilingual Task-Oriented Semantic Parsing Benchmark
Paper and Code
Aug 21, 2020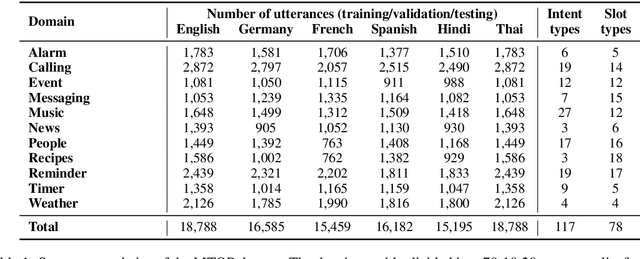
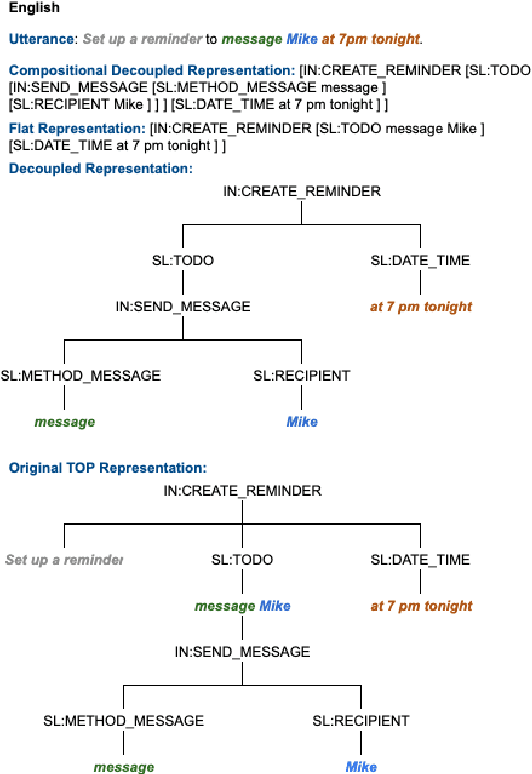
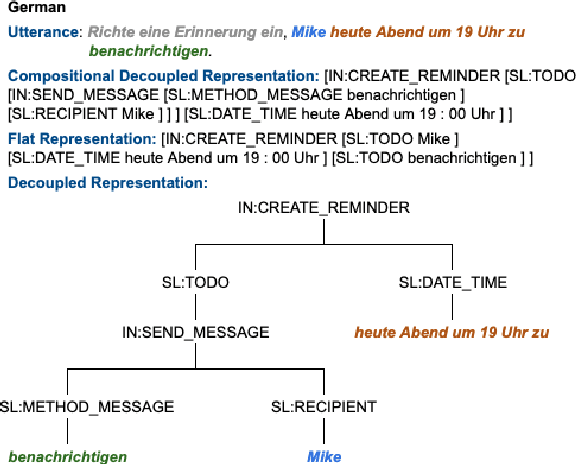
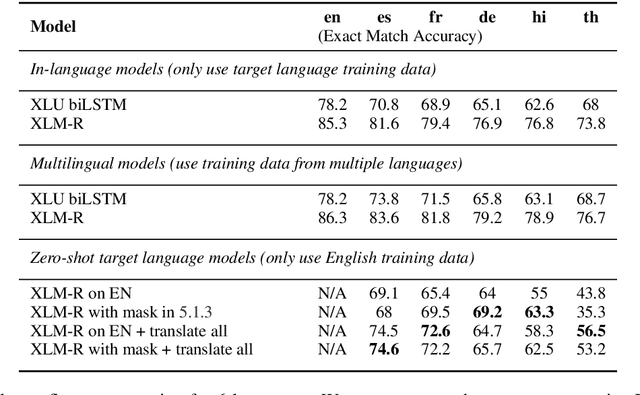
Scaling semantic parsing models for task-oriented dialog systems to new languages is often expensive and time-consuming due to the lack of available datasets. Even though few datasets are available, they suffer from many shortcomings: a) they contain few languages and small amounts of labeled data for other languages b) they are based on the simple intent and slot detection paradigm for non-compositional queries. In this paper, we present a new multilingual dataset, called MTOP, comprising of 100k annotated utterances in 6 languages across 11 domains. We use this dataset and other publicly available datasets to conduct a comprehensive benchmarking study on using various state-of-the-art multilingual pre-trained models for task-oriented semantic parsing. We achieve an average improvement of +6.3\% on Slot F1 for the two existing multilingual datasets, over best results reported in their experiments. Furthermore, we also demonstrate strong zero-shot performance using pre-trained models combined with automatic translation and alignment, and a proposed distant supervision method to reduce the noise in slot label projection.